 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview of Distant Supervision for Relation Extraction with a Focus on Denoising and Pre-training Methods
Paper and Code
Jul 17, 2022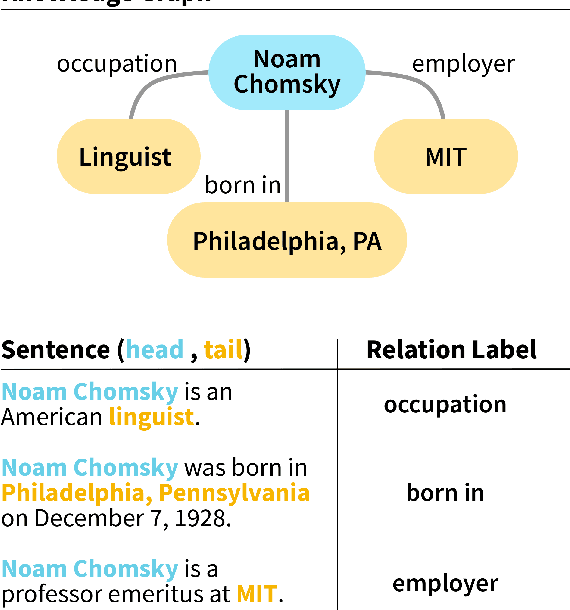



Relation Extraction (RE) is a foundational task of natural language processing. RE seeks to transform raw, unstructured text into structured knowledge by identifying relational information between entity pairs found in text. RE has numerous uses, such as knowledge graph completion, text summarization, question-answering, and search querying. The history of RE methods can be roughly organized into four phases: pattern-based RE, statistical-based RE, neural-based RE, and large language model-based RE. This survey begins with an overview of a few exemplary works in the earlier phases of RE, highlighting limitations and shortcomings to contextualize progress. Next, we review popular benchmarks and critically examine metrics used to assess RE performance. We then discuss distant supervision, a paradigm that has shaped the development of modern RE methods. Lastly, we review recent RE works focusing on denoising and pre-training methods.