 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of the effectiveness of Counterfactually Augmented Data
Paper and Code


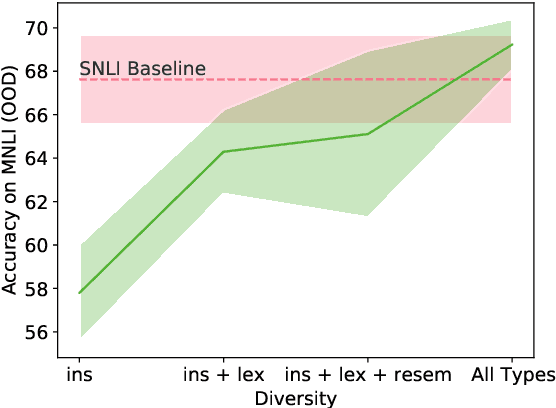

While pretrained language models achieve excellent performance on natural language understanding benchmarks, they tend to rely on spurious correlations and generalize poorly to out-of-distribution (OOD) data. Recent work has explored using counterfactually-augmented data (CAD) -- data generated by minimally perturbing examples to flip the ground-truth label -- to identify robust features that are invariant under distribution shift. However, empirical results using CAD for OOD generalization have been mixed. To explain this discrepancy, we draw insights from a linear Gaussian model and demonstrate the pitfalls of CAD. Specifically, we show that (a) while CAD is effective at identifying robust features, it may prevent the model from learning unperturbed robust features, and (b) CAD may exacerbate existing spurious correlations in the data. Our results show that the lack of perturbation diversity in current CAD datasets limits its effectiveness on OOD generalization, calling for innovative crowdsourcing procedures to elicit diverse perturbation of examples.