Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn initialization method for the k-means using the concept of useful nearest centers
Paper and Code
May 10, 2017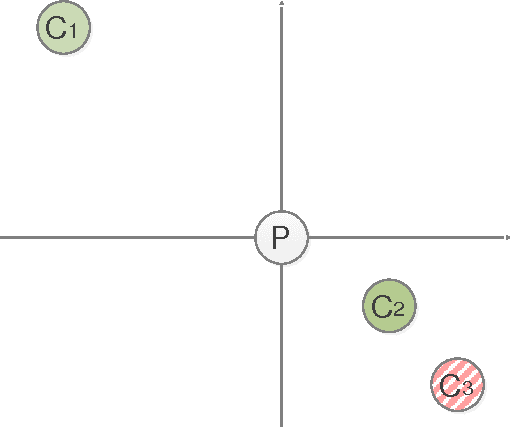
The aim of the k-means is to minimize squared sum of Euclidean distance from the mean (SSEDM) of each cluster. The k-means can effectively optimize this function, but it is too sensitive for initial centers (seeds). This paper proposed a method for initialization of the k-means using the concept of useful nearest center for each data point.
View paper on