 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Extraction Approach to Prescreen Heart Failure Patients for Clinical Trials
Paper and Code
Sep 06, 2016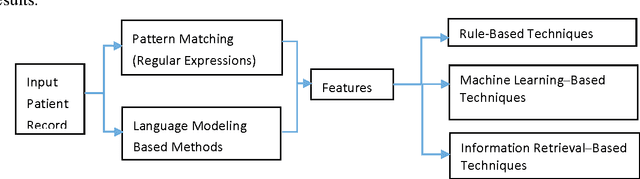
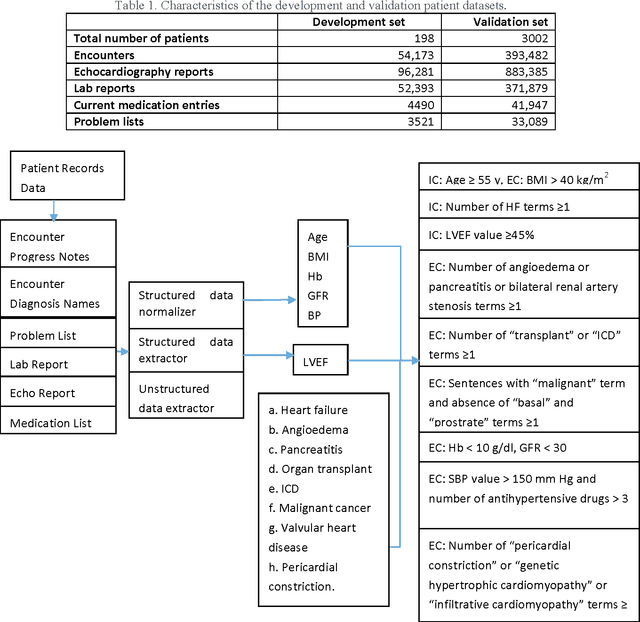
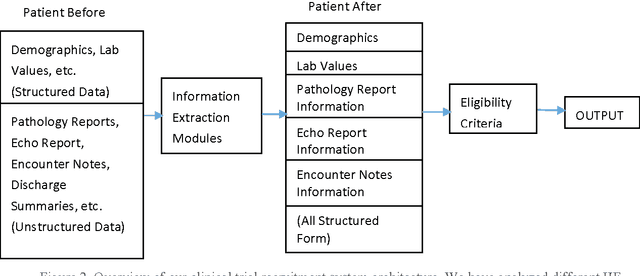
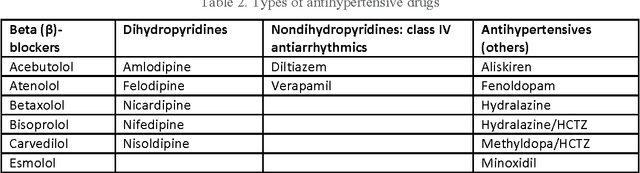
To reduce the large amount of time spent screening, identifying, and recruiting patients into clinical trials, we need prescreening systems that are able to automate the data extraction and decision-making tasks that are typically relegated to clinical research study coordinators. However, a major obstacle is the vast amount of patient data available as unstructured free-form text in electronic health records. Here we propose an information extraction-based approach that first automatically converts unstructured text into a structured form. The structured data are then compared against a list of eligibility criteria using a rule-based system to determine which patients qualify for enrollment in a heart failure clinical trial. We show that we can achieve highly accurate results, with recall and precision values of 0.95 and 0.86, respectively. Our system allowed us to significantly reduce the time needed for prescreening patients from a few weeks to a few minutes. Our open-source information extraction modules are available for researchers and could be tested and validated in other cardiovascular trials. An approach such as the one we demonstrate here may decrease costs and expedite clinical trials, and could enhance the reproducibility of trials across institutions and populations.