 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Approach for Estimating Social POI Boundaries With Textual Attributes on Social Media
Paper and Code
Dec 18, 2020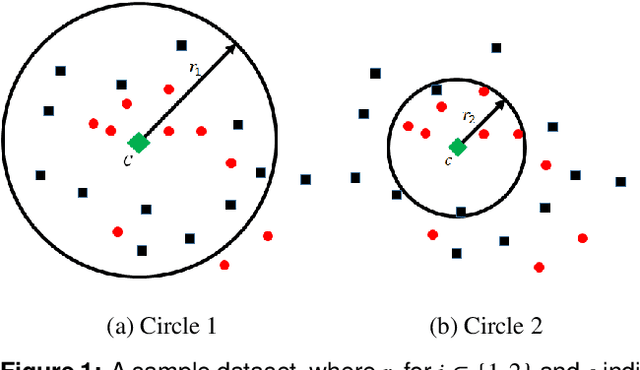
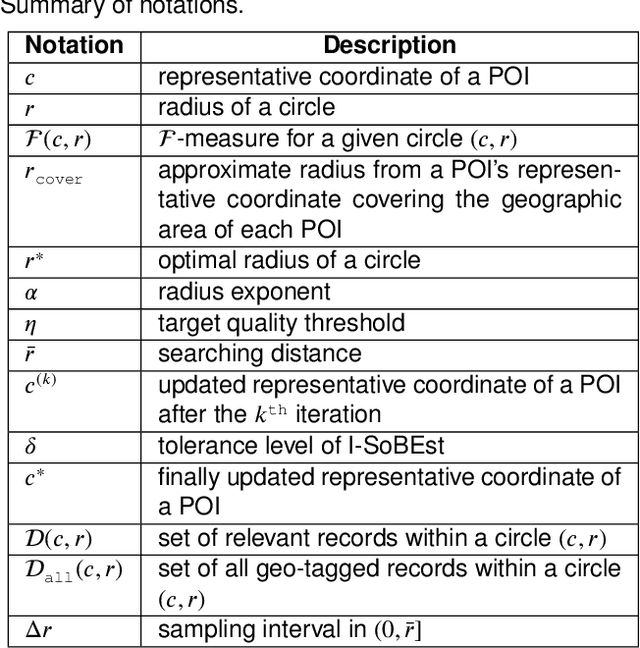

It has been insufficiently explored how to perform density-based clustering by exploiting textual attributes on social media. In this paper, we aim at discovering a social point-of-interest (POI) boundary, formed as a convex polygon. More specifically, we present a new approach and algorithm, built upon our earlier work on social POI boundary estimation (SoBEst). This SoBEst approach takes into account both relevant and irrelevant records within a geographic area, where relevant records contain a POI name or its variations in their text field. Our study is motivated by the following empirical observation: a fixed representative coordinate of each POI that SoBEst basically assumes may be far away from the centroid of the estimated social POI boundary for certain POIs. Thus, using SoBEst in such cases may possibly result in unsatisfactory performance on the boundary estimation quality (BEQ), which is expressed as a function of the $F$-measure. To solve this problem, we formulate a joint optimization problem of simultaneously finding the radius of a circle and the POI's representative coordinate $c$ by allowing to update $c$. Subsequently, we design an iterative SoBEst (I-SoBEst) algorithm, which enables us to achieve a higher degree of BEQ for some POIs. The computational complexity of the proposed I-SoBEst algorithm is shown to scale linearly with the number of records. We demonstrate the superiority of our algorithm over competing clustering methods including the original SoBEst.