 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Study of Log Placement Recommendation in an Enterprise System
Paper and Code
Mar 10, 2021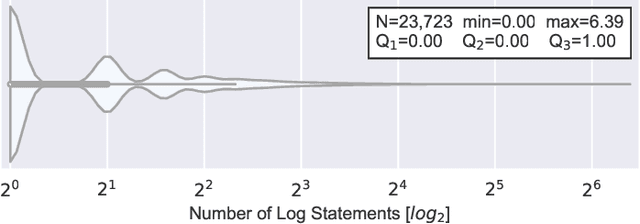



Logging is a development practice that plays an important role in the operations and monitoring of complex systems. Developers place log statements in the source code and use log data to understand how the system behaves in production. Unfortunately, anticipating where to log during development is challenging. Previous studies show the feasibility of leveraging machine learning to recommend log placement despite the data imbalance since logging is a fraction of the overall code base. However, it remains unknown how those techniques apply to an industry setting, and little is known about the effect of imbalanced data and sampling techniques. In this paper, we study the log placement problem in the code base of Adyen, a large-scale payment company. We analyze 34,526 Java files and 309,527 methods that sum up +2M SLOC. We systematically measure the effectiveness of five models based on code metrics, explore the effect of sampling techniques, understand which features models consider to be relevant for the prediction, and evaluate whether we can exploit 388,086 methods from 29 Apache projects to learn where to log in an industry setting. Our best performing model achieves 79% of balanced accuracy, 81% of precision, 60% of recall. While sampling techniques improve recall, they penalize precision at a prohibitive cost. Experiments with open-source data yield under-performing models over Adyen's test set; nevertheless, they are useful due to their low rate of false positives. Our supporting scripts and tools are available to the community.