Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Multi-Module Audio Deepfake Generation System for ADD Challenge 2023
Paper and Code
Jul 03, 2023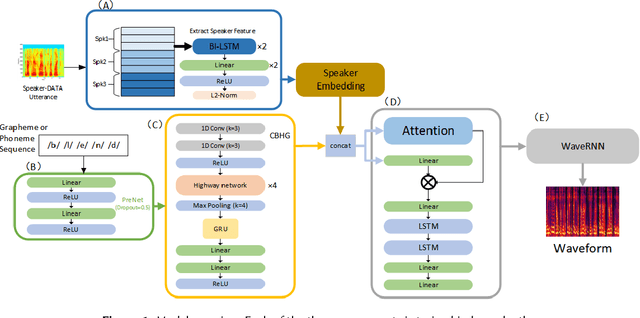
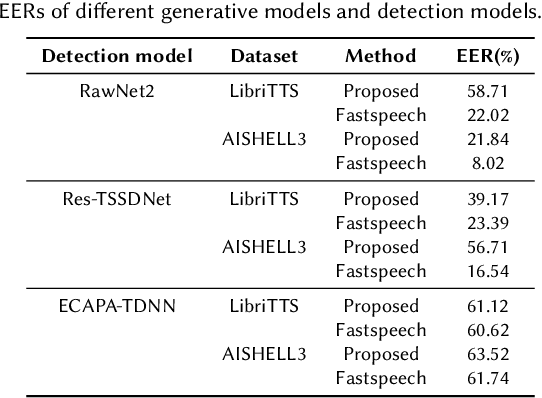
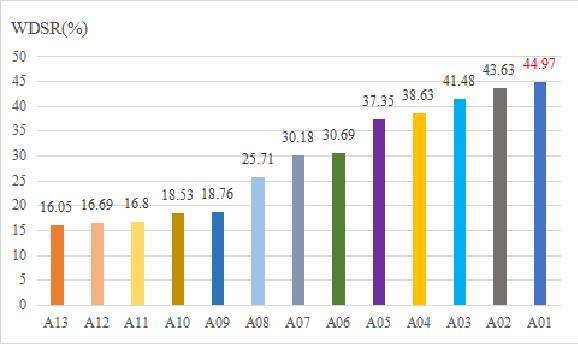
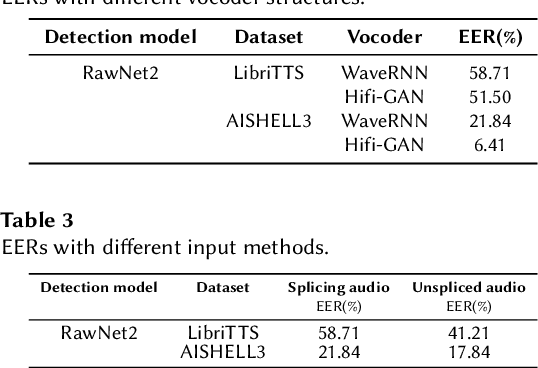
The task of synthetic speech generation is to generate language content from a given text, then simulating fake human voice.The key factors that determine the effect of synthetic speech generation mainly include speed of generation, accuracy of word segmentation, naturalness of synthesized speech, etc. This paper builds an end-to-end multi-module synthetic speech generation model, including speaker encoder, synthesizer based on Tacotron2, and vocoder based on WaveRNN. In addition, we perform a lot of comparative experiments on different datasets and various model structures. Finally, we won the first place in the ADD 2023 challenge Track 1.1 with the weighted deception success rate (WDSR) of 44.97%.
View paper on