 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Baseline for Video Captioning
Paper and Code


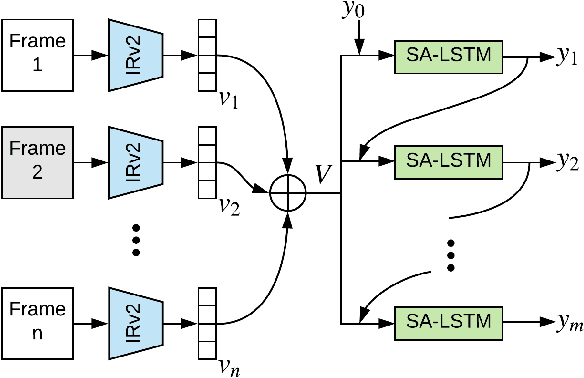
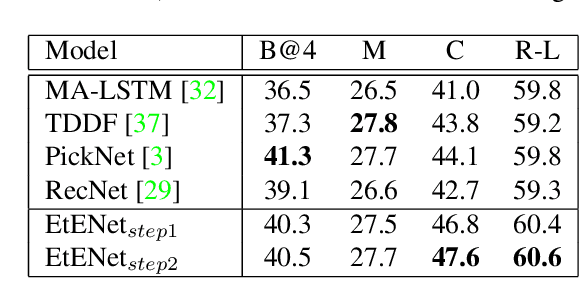
Building correspondences across different modalities, such as video and language, has recently become critical in many visual recognition applications, such as video captioning. Inspired by machine translation, recent models tackle this task using an encoder-decoder strategy. The (video) encoder is traditionally a Convolutional Neural Network (CNN), while the decoding (for language generation) is done using a Recurrent Neural Network (RNN). Current state-of-the-art methods, however, train encoder and decoder separately. CNNs are pretrained on object and/or action recognition tasks and used to encode video-level features. The decoder is then optimised on such static features to generate the video's description. This disjoint setup is arguably sub-optimal for input (video) to output (description) mapping. In this work, we propose to optimise both encoder and decoder simultaneously in an end-to-end fashion. In a two-stage training setting, we first initialise our architecture using pre-trained encoders and decoders -- then, the entire network is trained end-to-end in a fine-tuning stage to learn the most relevant features for video caption generation. In our experiments, we use GoogLeNet and Inception-ResNet-v2 as encoders and an original Soft-Attention (SA-) LSTM as a decoder. Analogously to gains observed in other computer vision problems, we show that end-to-end training significantly improves over the traditional, disjoint training process. We evaluate our End-to-End (EtENet) Networks on the Microsoft Research Video Description (MSVD) and the MSR Video to Text (MSR-VTT) benchmark datasets, showing how EtENet achieves state-of-the-art performance across the board.