 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Measuring the Similarity of Sentential Arguments with Language Model Domain Adaptation
Paper and Code
Feb 19, 2021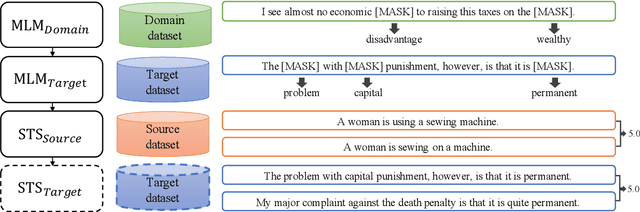

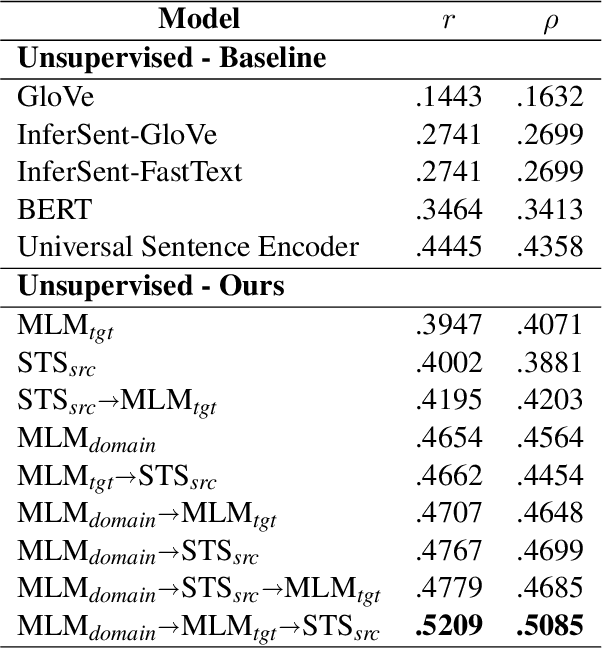
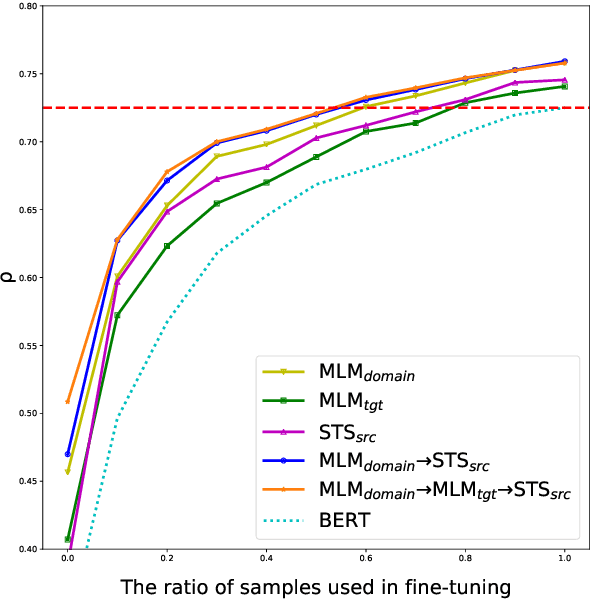
Measuring the similarity between two different sentential arguments is an important task in argument mining. However, one of the challenges in this field is that the dataset must be annotated using expertise in a variety of topics, making supervised learning with labeled data expensive. In this paper, we investigated whether this problem could be alleviated through transfer learning. We first adapted a pretrained language model to a domain of interest using self-supervised learning. Then, we fine-tuned the model to a task of measuring the similarity between sentences taken from different domains. Our approach improves a correlation with human-annotated similarity scores compared to competitive baseline models on the Argument Facet Similarity dataset in an unsupervised setting. Moreover, we achieve comparable performance to a fully supervised baseline model by using only about 60% of the labeled data samples. We believe that our work suggests the possibility of a generalized argument clustering model for various argumentative topics.