Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Extrapolation in Text Generation with Scalar Control
Paper and Code
Apr 16, 2021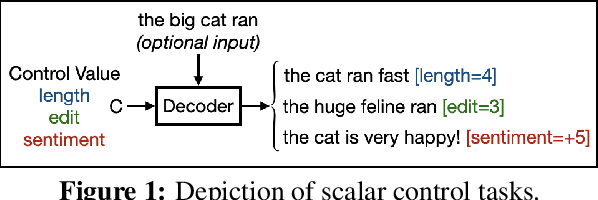
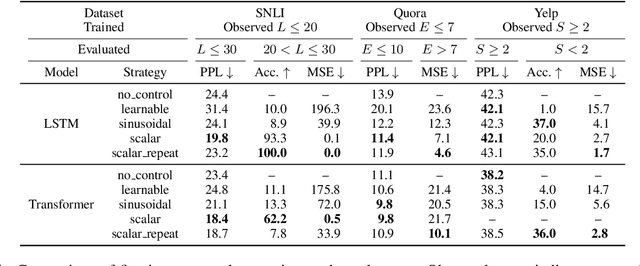
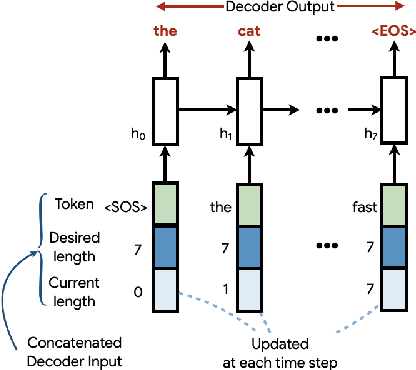
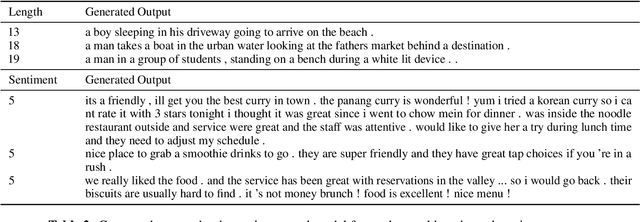
We conduct an empirical evaluation of extrapolation performance when conditioning on scalar control inputs like desired output length, desired edit from an input sentence, and desired sentiment across three text generation tasks. Specifically, we examine a zero-shot setting where models are asked to generalize to ranges of control values not seen during training. We focus on evaluating popular embedding methods for scalar inputs, including both learnable and sinusoidal embeddings, as well as simpler approaches. Surprisingly, our findings indicate that the simplest strategy of using scalar inputs directly, without further encoding, most reliably allows for successful extrapolation.
View paper on