Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Accuracy, Fairness, Explainability, Distributional Robustness, and Adversarial Robustness
Paper and Code
Sep 29, 2021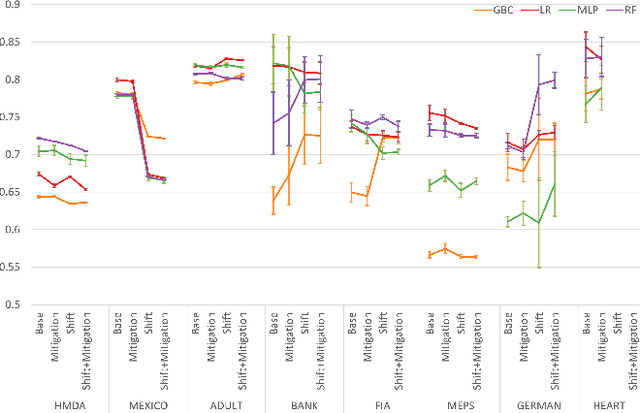
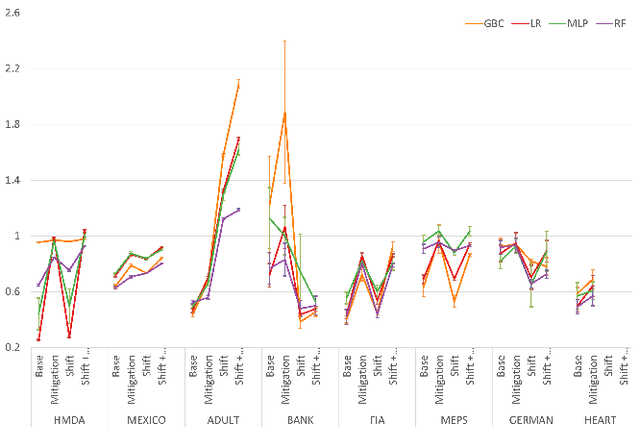
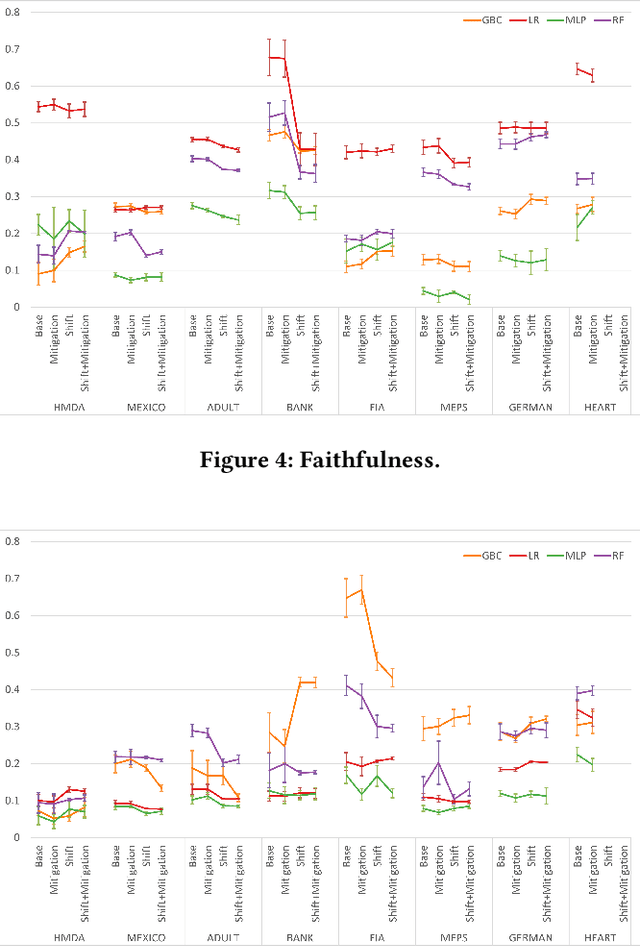
To ensure trust in AI models, it is becoming increasingly apparent that evaluation of models must be extended beyond traditional performance metrics, like accuracy, to other dimensions, such as fairness, explainability, adversarial robustness, and distribution shift. We describe an empirical study to evaluate multiple model types on various metrics along these dimensions on several datasets. Our results show that no particular model type performs well on all dimensions, and demonstrate the kinds of trade-offs involved in selecting models evaluated along multiple dimensions.
* presented at the 2021 KDD Workshop on Measures and Best Practices
for Responsible AI
View paper on