 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Sketched SVD and its Application to Leverage Score Ordering
Paper and Code
Dec 19, 2018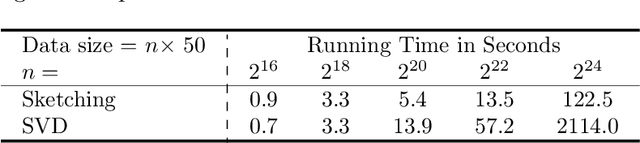
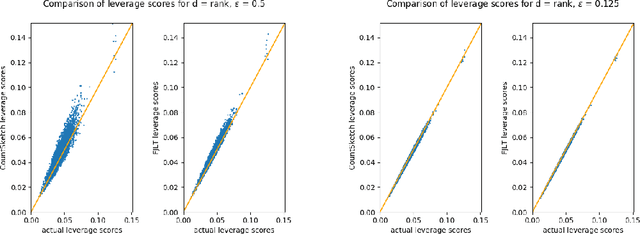

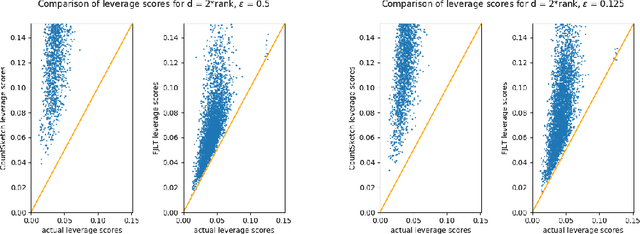
The power of randomized algorithms in numerical methods have led to fast solutions which use the Singular Value Decomposition (SVD) as a core routine. However, given the large data size of modern and the modest runtime of SVD, most practical algorithms would require some form of approximation, such as sketching, when running SVD. While these approximation methods satisfy many theoretical guarantees, we provide the first algorithmic implementations for sketch-and-solve SVD problems on real-world, large-scale datasets. We provide a comprehensive empirical evaluation of these algorithms and provide guidelines on how to ensure accurate deployment to real-world data. As an application of sketched SVD, we present Sketched Leverage Score Ordering, a technique for determining the ordering of data in the training of neural networks. Our technique is based on the distributed computation of leverage scores using random projections. These computed leverage scores provide a flexible and efficient method to determine the optimal ordering of training data without manual intervention or annotations. We present empirical results on an extensive set of experiments across image classification, language sentiment analysis, and multi-modal sentiment analysis. Our method is faster compared to standard randomized projection algorithms and shows improvements in convergence and results.