 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Effective Transformer Decoder-Based Framework for Multi-Task Visual Grounding
Paper and Code

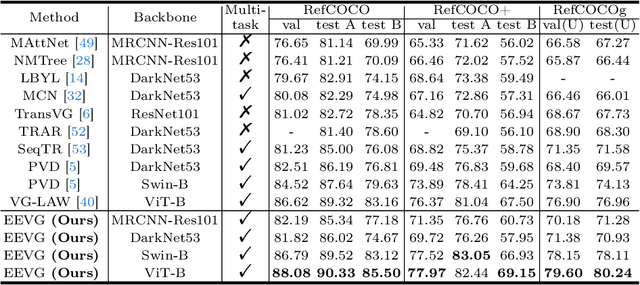


Most advanced visual grounding methods rely on Transformers for visual-linguistic feature fusion. However, these Transformer-based approaches encounter a significant drawback: the computational costs escalate quadratically due to the self-attention mechanism in the Transformer Encoder, particularly when dealing with high-resolution images or long context sentences. This quadratic increase in computational burden restricts the applicability of visual grounding to more intricate scenes, such as conversation-based reasoning segmentation, which involves lengthy language expressions. In this paper, we propose an efficient and effective multi-task visual grounding (EEVG) framework based on Transformer Decoder to address this issue, which reduces the cost in both language and visual aspects. In the language aspect, we employ the Transformer Decoder to fuse visual and linguistic features, where linguistic features are input as memory and visual features as queries. This allows fusion to scale linearly with language expression length. In the visual aspect, we introduce a parameter-free approach to reduce computation by eliminating background visual tokens based on attention scores. We then design a light mask head to directly predict segmentation masks from the remaining sparse feature maps. Extensive results and ablation studies on benchmarks demonstrate the efficiency and effectiveness of our approach. Code is available in https://github.com/chenwei746/EEVG.