 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Anchor-free Universal Lesion Detection in CT-scans
Paper and Code
Mar 30, 2022
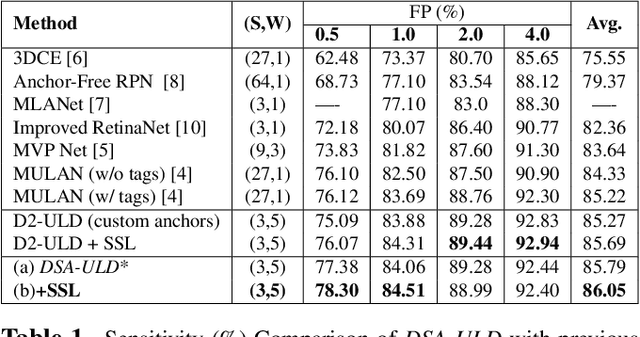
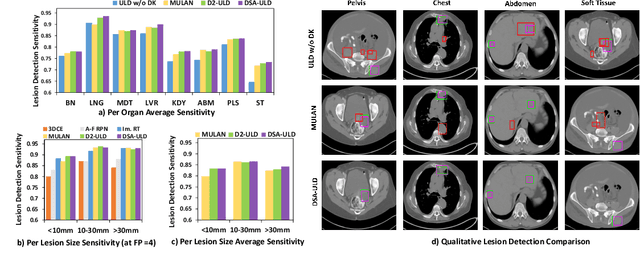
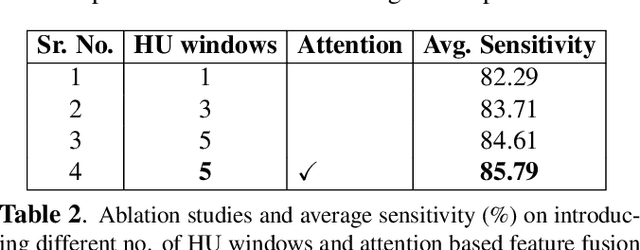
Existing universal lesion detection (ULD) methods utilize compute-intensive anchor-based architectures which rely on predefined anchor boxes, resulting in unsatisfactory detection performance, especially in small and mid-sized lesions. Further, these default fixed anchor-sizes and ratios do not generalize well to different datasets. Therefore, we propose a robust one-stage anchor-free lesion detection network that can perform well across varying lesions sizes by exploiting the fact that the box predictions can be sorted for relevance based on their center rather than their overlap with the object. Furthermore, we demonstrate that the ULD can be improved by explicitly providing it the domain-specific information in the form of multi-intensity images generated using multiple HU windows, followed by self-attention based feature-fusion and backbone initialization using weights learned via self-supervision over CT-scans. We obtain comparable results to the state-of-the-art methods, achieving an overall sensitivity of 86.05% on the DeepLesion dataset, which comprises of approximately 32K CT-scans with lesions annotated across various body organs.