 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Automatic Image Annotation Model Via Attention Model and Data Equilibrium
Paper and Code
Jan 26, 2020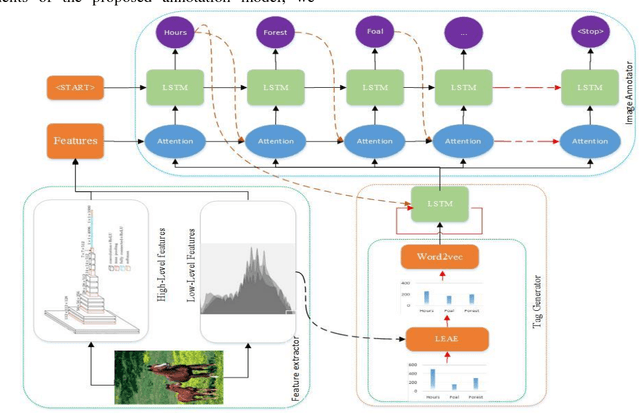
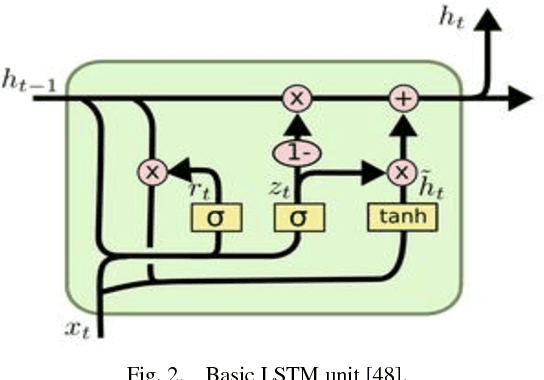

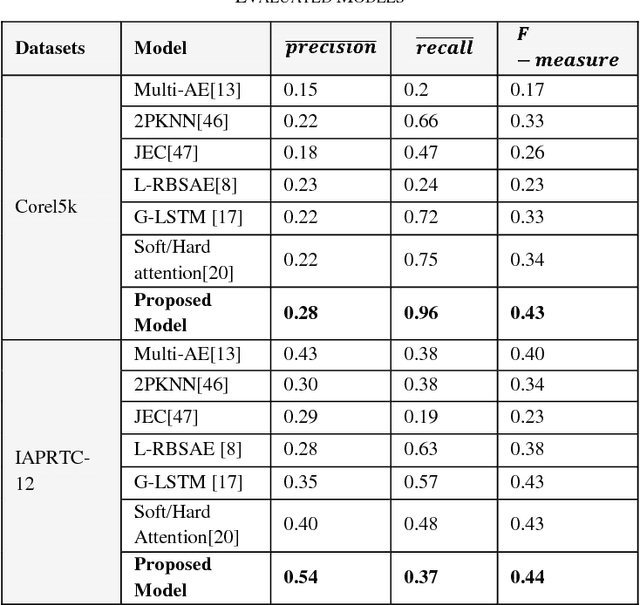
Nowadays, a huge number of images are available. However, retrieving a required image for an ordinary user is a challenging task in computer vision systems. During the past two decades, many types of research have been introduced to improve the performance of the automatic annotation of images, which are traditionally focused on content-based image retrieval. Although, recent research demonstrates that there is a semantic gap between content-based image retrieval and image semantics understandable by humans. As a result, existing research in this area has caused to bridge the semantic gap between low-level image features and high-level semantics. The conventional method of bridging the semantic gap is through the automatic image annotation (AIA) that extracts semantic features using machine learning techniques. In this paper, we propose a novel AIA model based on the deep learning feature extraction method. The proposed model has three phases, including a feature extractor, a tag generator, and an image annotator. First, the proposed model extracts automatically the high and low-level features based on dual-tree continues wavelet transform (DT-CWT), singular value decomposition, distribution of color ton, and the deep neural network. Moreover, the tag generator balances the dictionary of the annotated keywords by a new log-entropy auto-encoder (LEAE) and then describes these keywords by word embedding. Finally, the annotator works based on the long-short-term memory (LSTM) network in order to obtain the importance degree of specific features of the image. The experiments conducted on two benchmark datasets confirm that the superiority of the proposed model compared to the previous models in terms of performance criteria.