 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Paper and Code


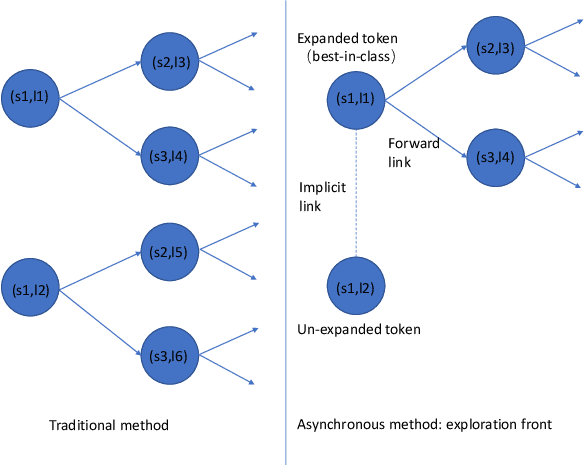

We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.