 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach for Auto Generation of Labeling Functions for Software Engineering Chatbots
Paper and Code
Oct 09, 2024

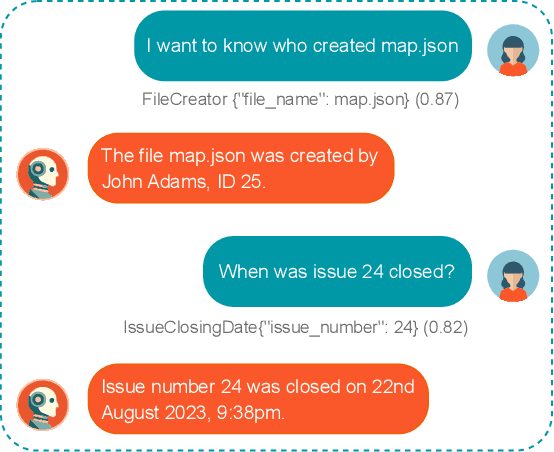
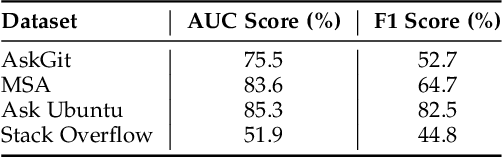
Software engineering (SE) chatbots are increasingly gaining attention for their role in enhancing development processes. At the core of chatbots are the Natural Language Understanding platforms (NLUs), which enable them to comprehend and respond to user queries. Before deploying NLUs, there is a need to train them with labeled data. However, acquiring such labeled data for SE chatbots is challenging due to the scarcity of high-quality datasets. This challenge arises because training SE chatbots requires specialized vocabulary and phrases not found in typical language datasets. Consequently, chatbot developers often resort to manually annotating user queries to gather the data necessary for training effective chatbots, a process that is both time-consuming and resource-intensive. Previous studies propose approaches to support chatbot practitioners in annotating users' posed queries. However, these approaches require human intervention to generate rules, called labeling functions (LFs), that identify and categorize user queries based on specific patterns in the data. To address this issue, we propose an approach to automatically generate LFs by extracting patterns from labeled user queries. We evaluate the effectiveness of our approach by applying it to the queries of four diverse SE datasets (namely AskGit, MSA, Ask Ubuntu, and Stack Overflow) and measure the performance improvement gained from training the NLU on the queries labeled by the generated LFs. We find that the generated LFs effectively label data with AUC scores of up to 85.3%, and NLU's performance improvement of up to 27.2% across the studied datasets. Furthermore, our results show that the number of LFs used to generate LFs affects the labeling performance. We believe that our approach can save time and resources in labeling users' queries, allowing practitioners to focus on core chatbot functionalities.