 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Alternative to Backpropagation in Deep Reinforcement Learning
Paper and Code
Oct 15, 2020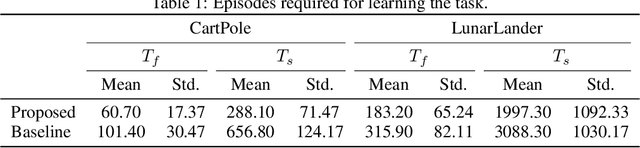



State-of-the-art deep learning algorithms mostly rely on gradient backpropagation to train a deep artificial neural network, which is generally regarded to be biologically implausible. For a network of stochastic units trained on a reinforcement learning task or a supervised learning task, one biologically plausible way of learning is to train each unit by REINFORCE. In this case, only a global reward signal has to be broadcast to all units, and the learning rule given is local, which can be interpreted as reward-modulated spike-timing-dependent plasticity (R-STDP) that is observed biologically. Although this learning rule follows the gradient of return in expectation, it suffers from high variance and cannot be used to train a deep network in practice. In this paper, we propose an algorithm called MAP propagation that can reduce this variance significantly while retaining the local property of learning rule. Different from prior works on local learning rules (e.g. Contrastive Divergence) which mostly applies to undirected models in unsupervised learning tasks, our proposed algorithm applies to directed models in reinforcement learning tasks. We show that the newly proposed algorithm can solve common reinforcement learning tasks at a speed similar to that of backpropagation when applied to an actor-critic network.