Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Algorithm for Online K-Means Clustering
Paper and Code
Feb 23, 2015


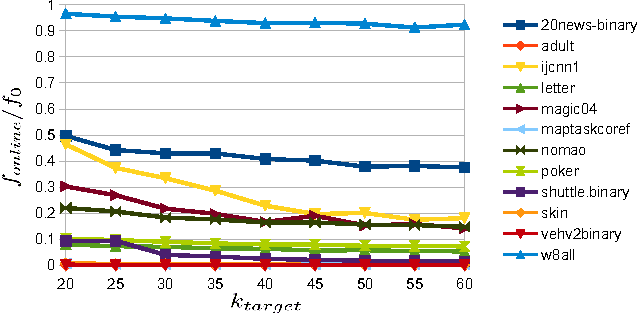
This paper shows that one can be competitive with the k-means objective while operating online. In this model, the algorithm receives vectors v_1,...,v_n one by one in an arbitrary order. For each vector the algorithm outputs a cluster identifier before receiving the next one. Our online algorithm generates ~O(k) clusters whose k-means cost is ~O(W*). Here, W* is the optimal k-means cost using k clusters and ~O suppresses poly-logarithmic factors. We also show that, experimentally, it is not much worse than k-means++ while operating in a strictly more constrained computational model.
View paper on