 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn adaptive synchronization approach for weights of deep reinforcement learning
Paper and Code
Aug 16, 2020
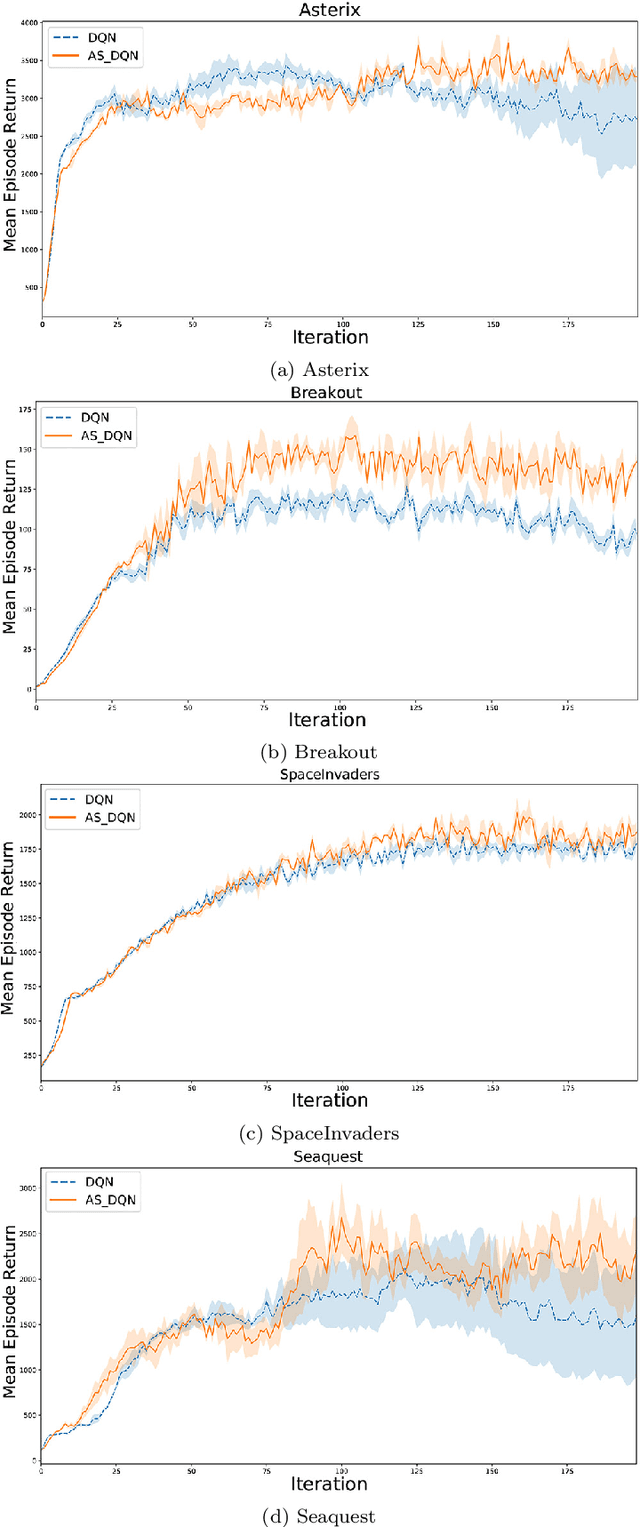
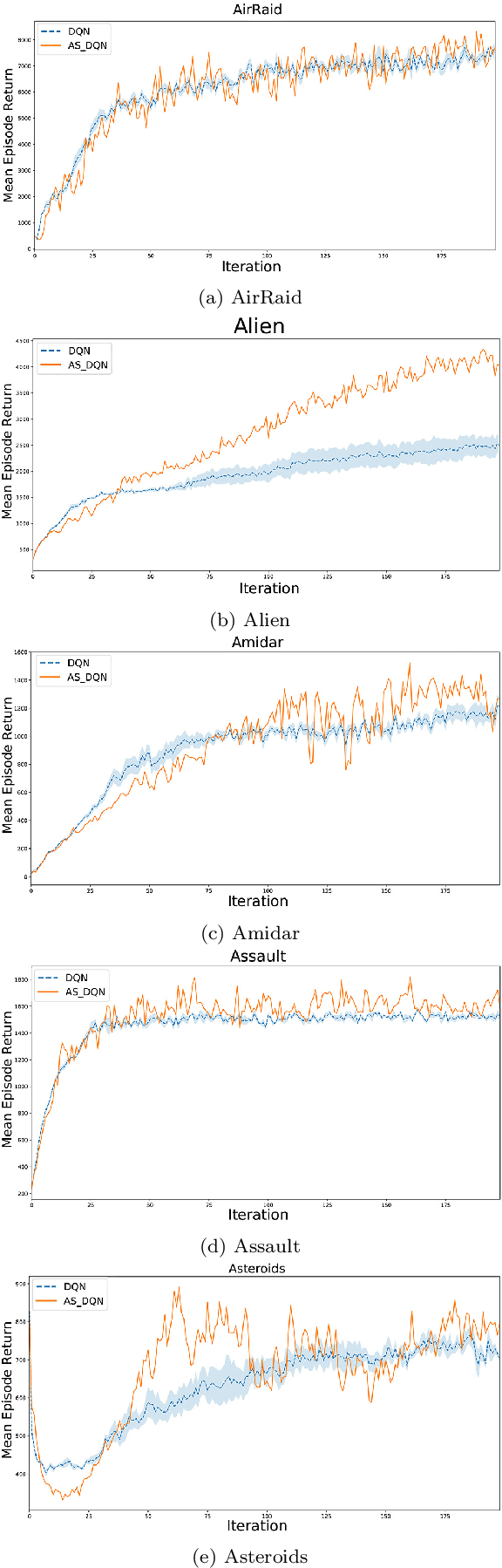
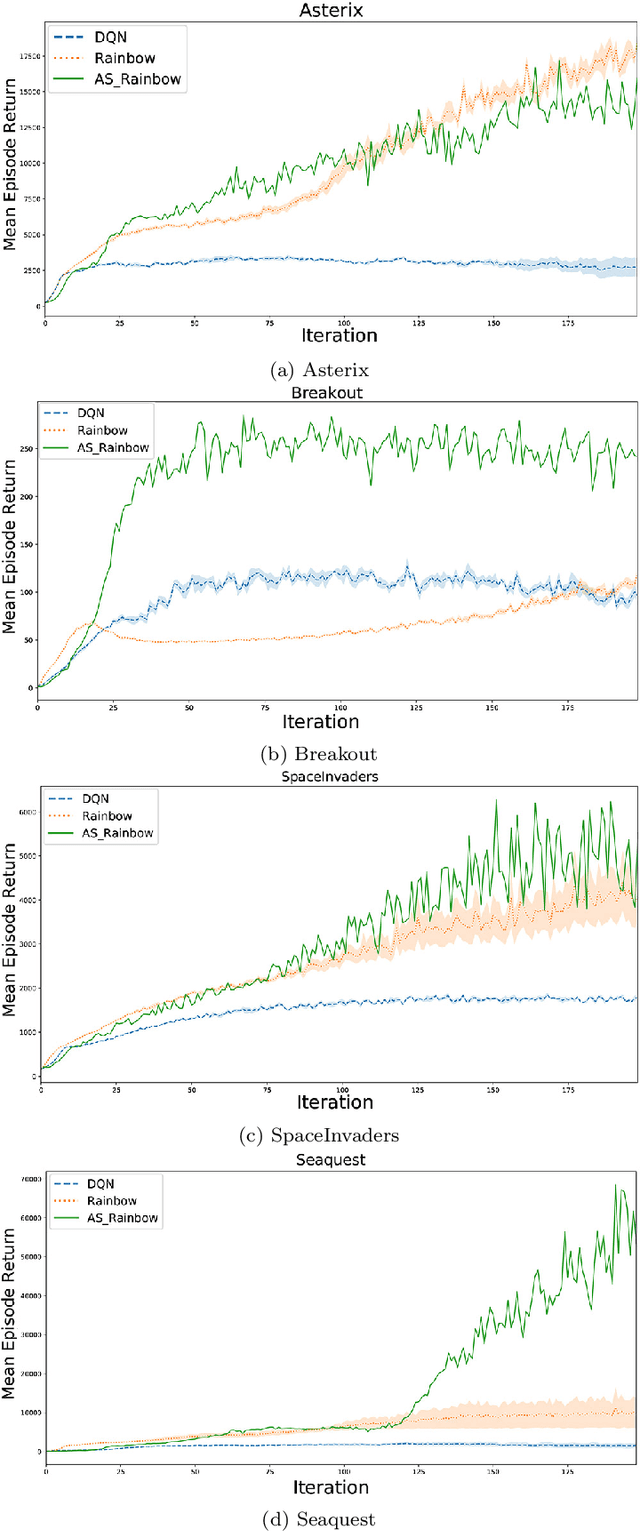
Deep Q-Networks (DQN) is one of the most well-known methods of deep reinforcement learning, which uses deep learning to approximate the action-value function. Solving numerous Deep reinforcement learning challenges such as moving targets problem and the correlation between samples are the main advantages of this model. Although there have been various extensions of DQN in recent years, they all use a similar method to DQN to overcome the problem of moving targets. Despite the advantages mentioned, synchronizing the network weight in a fixed step size, independent of the agent's behavior, may in some cases cause the loss of some properly learned networks. These lost networks may lead to states with more rewards, hence better samples stored in the replay memory for future training. In this paper, we address this problem from the DQN family and provide an adaptive approach for the synchronization of the neural weights used in DQN. In this method, the synchronization of weights is done based on the recent behavior of the agent, which is measured by a criterion at the end of the intervals. To test this method, we adjusted the DQN and rainbow methods with the proposed adaptive synchronization method. We compared these adjusted methods with their standard form on well-known games, which results confirm the quality of our synchronization methods.