 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmpleGCG: Learning a Universal and Transferable Generative Model of Adversarial Suffixes for Jailbreaking Both Open and Closed LLMs
Paper and Code

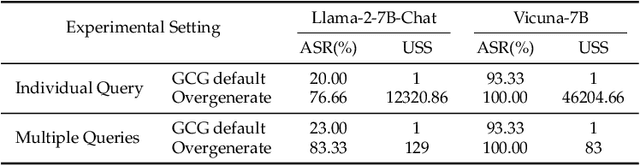
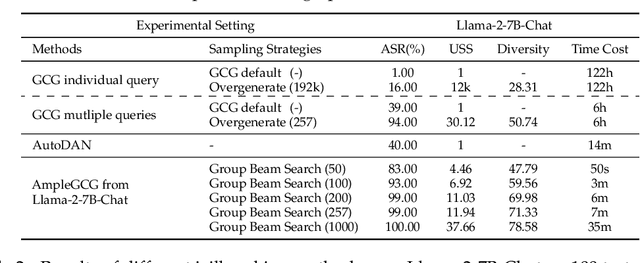

As large language models (LLMs) become increasingly prevalent and integrated into autonomous systems, ensuring their safety is imperative. Despite significant strides toward safety alignment, recent work GCG~\citep{zou2023universal} proposes a discrete token optimization algorithm and selects the single suffix with the lowest loss to successfully jailbreak aligned LLMs. In this work, we first discuss the drawbacks of solely picking the suffix with the lowest loss during GCG optimization for jailbreaking and uncover the missed successful suffixes during the intermediate steps. Moreover, we utilize those successful suffixes as training data to learn a generative model, named AmpleGCG, which captures the distribution of adversarial suffixes given a harmful query and enables the rapid generation of hundreds of suffixes for any harmful queries in seconds. AmpleGCG achieves near 100\% attack success rate (ASR) on two aligned LLMs (Llama-2-7B-chat and Vicuna-7B), surpassing two strongest attack baselines. More interestingly, AmpleGCG also transfers seamlessly to attack different models, including closed-source LLMs, achieving a 99\% ASR on the latest GPT-3.5. To summarize, our work amplifies the impact of GCG by training a generative model of adversarial suffixes that is universal to any harmful queries and transferable from attacking open-source LLMs to closed-source LLMs. In addition, it can generate 200 adversarial suffixes for one harmful query in only 4 seconds, rendering it more challenging to defend.