 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Between Spectral and Spatial Estimation for Speech Separation and Enhancement
Paper and Code
Nov 18, 2019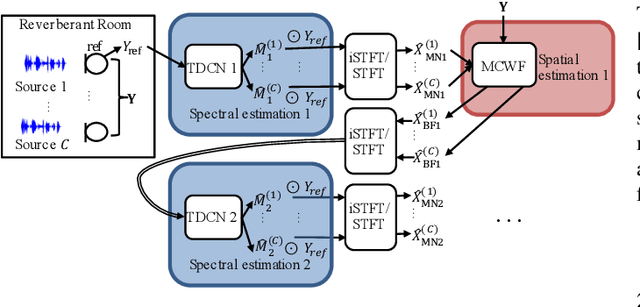
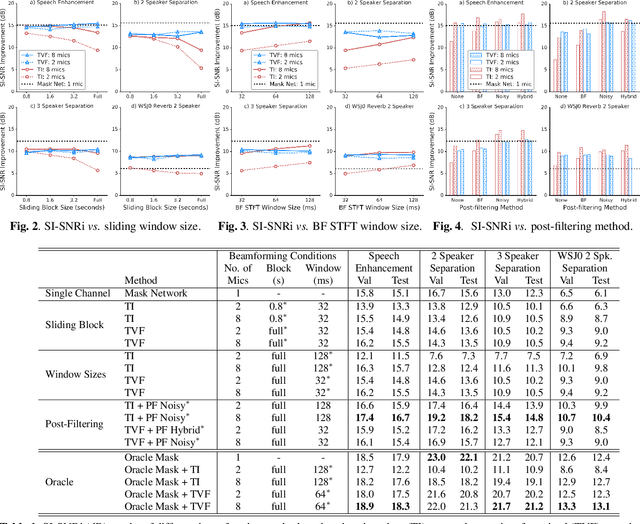
This work investigates alternation between spectral separation using masking-based networks and spatial separation using multichannel beamforming. In this framework, the spectral separation is performed using a mask-based deep network. The result of mask-based separation is used, in turn, to estimate a spatial beamformer. The output of the beamformer is fed back into another mask-based separation network. We explore multiple ways of computing time-varying covariance matrices to improve beamforming, including factorizing the spatial covariance into a time-varying amplitude component and time-invariant spatial component. For the subsequent mask-based filtering, we consider different modes, including masking the noisy input, masking the beamformer output, and a hybrid approach combining both. Our best method first uses spectral separation, then spatial beamforming, and finally a spectral post-filter, and demonstrates an average improvement of 2.8 dB over baseline mask-based separation, across four different reverberant speech enhancement and separation tasks.