 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Image-Word Representations Improve Inductive Transfer Across Vision-Language Tasks
Paper and Code
Oct 16, 2017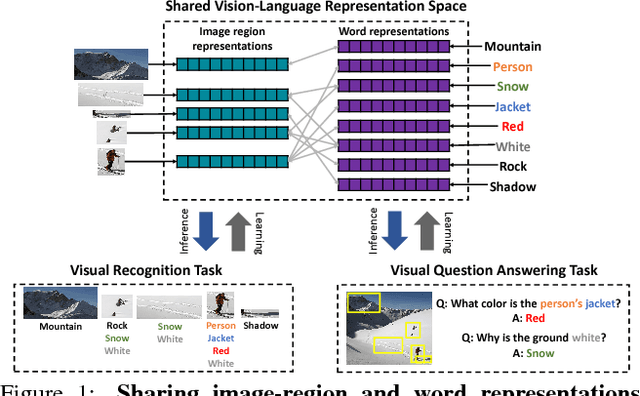

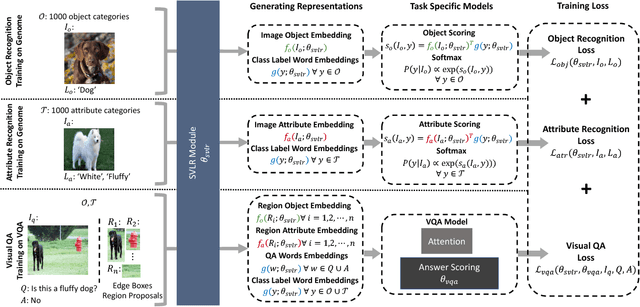
An important goal of computer vision is to build systems that learn visual representations over time that can be applied to many tasks. In this paper, we investigate a vision-language embedding as a core representation and show that it leads to better cross-task transfer than standard multi-task learning. In particular, the task of visual recognition is aligned to the task of visual question answering by forcing each to use the same word-region embeddings. We show this leads to greater inductive transfer from recognition to VQA than standard multitask learning. Visual recognition also improves, especially for categories that have relatively few recognition training labels but appear often in the VQA setting. Thus, our paper takes a small step towards creating more general vision systems by showing the benefit of interpretable, flexible, and trainable core representations.