 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostic proper learning of monotone functions: beyond the black-box correction barrier
Paper and Code
Apr 18, 2023

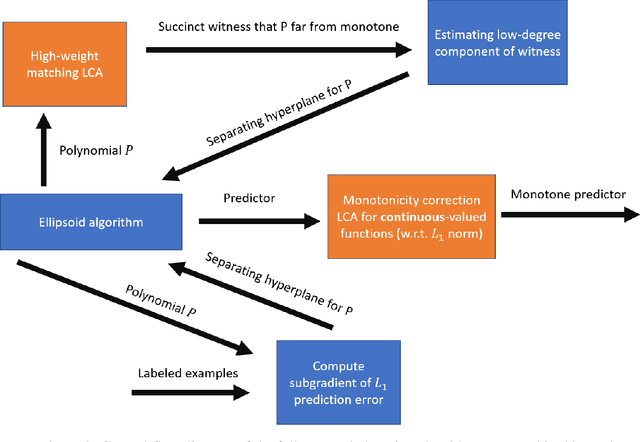
We give the first agnostic, efficient, proper learning algorithm for monotone Boolean functions. Given $2^{\tilde{O}(\sqrt{n}/\varepsilon)}$ uniformly random examples of an unknown function $f:\{\pm 1\}^n \rightarrow \{\pm 1\}$, our algorithm outputs a hypothesis $g:\{\pm 1\}^n \rightarrow \{\pm 1\}$ that is monotone and $(\mathrm{opt} + \varepsilon)$-close to $f$, where $\mathrm{opt}$ is the distance from $f$ to the closest monotone function. The running time of the algorithm (and consequently the size and evaluation time of the hypothesis) is also $2^{\tilde{O}(\sqrt{n}/\varepsilon)}$, nearly matching the lower bound of Blais et al (RANDOM '15). We also give an algorithm for estimating up to additive error $\varepsilon$ the distance of an unknown function $f$ to monotone using a run-time of $2^{\tilde{O}(\sqrt{n}/\varepsilon)}$. Previously, for both of these problems, sample-efficient algorithms were known, but these algorithms were not run-time efficient. Our work thus closes this gap in our knowledge between the run-time and sample complexity. This work builds upon the improper learning algorithm of Bshouty and Tamon (JACM '96) and the proper semiagnostic learning algorithm of Lange, Rubinfeld, and Vasilyan (FOCS '22), which obtains a non-monotone Boolean-valued hypothesis, then ``corrects'' it to monotone using query-efficient local computation algorithms on graphs. This black-box correction approach can achieve no error better than $2\mathrm{opt} + \varepsilon$ information-theoretically; we bypass this barrier by a) augmenting the improper learner with a convex optimization step, and b) learning and correcting a real-valued function before rounding its values to Boolean. Our real-valued correction algorithm solves the ``poset sorting'' problem of [LRV22] for functions over general posets with non-Boolean labels.