Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAge Group Classification with Speech and Metadata Multimodality Fusion
Paper and Code
Mar 02, 2018

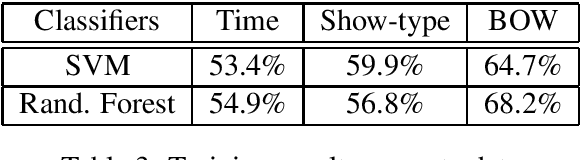

Children comprise a significant proportion of TV viewers and it is worthwhile to customize the experience for them. However, identifying who is a child in the audience can be a challenging task. Identifying gender and age from audio commands is a well-studied problem but is still very challenging to get good accuracy when the utterances are typically only a couple of seconds long. We present initial studies of a novel method which combines utterances with user metadata. In particular, we develop an ensemble of different machine learning techniques on different subsets of data to improve child detection. Our initial results show a 9.2\% absolute improvement over the baseline, leading to a state-of-the-art performance.
* Proceedings of the 15th Conference of the European Chapter of the
Association for Computational Linguistics: Volume 2, Short Papers, 2017
View paper on