 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFR-Net: Attention-Driven Fingerprint Recognition Network
Paper and Code
Dec 03, 2022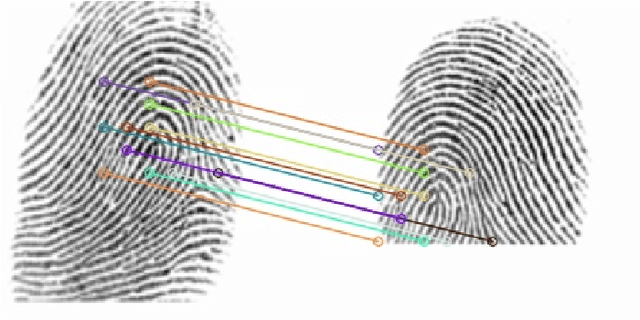
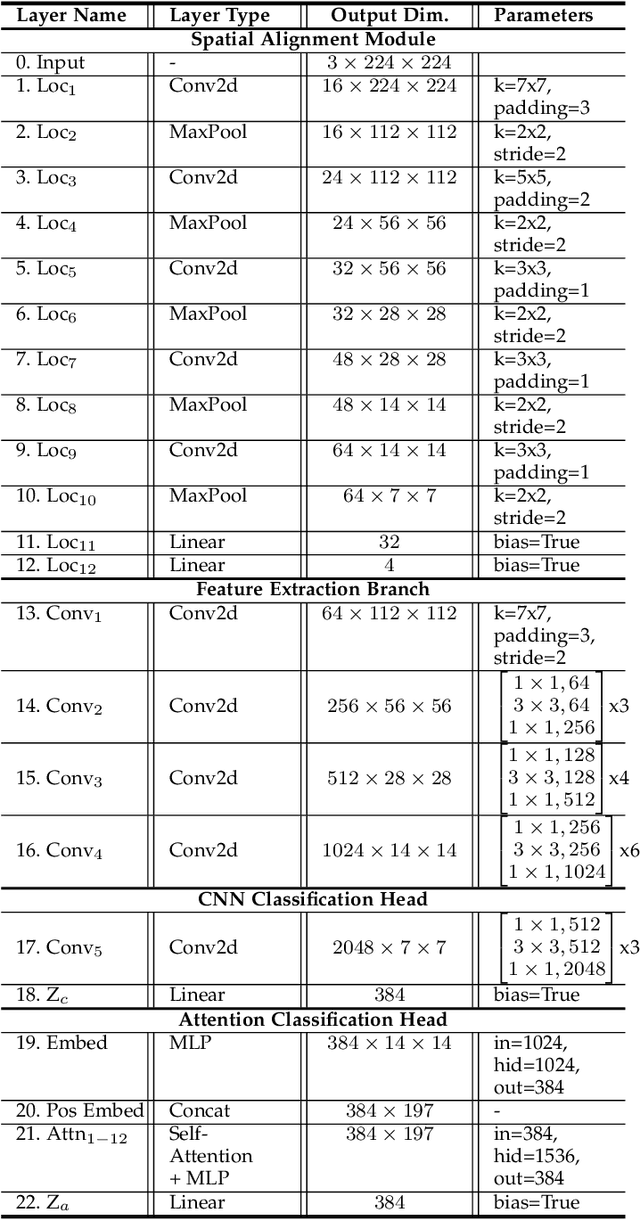
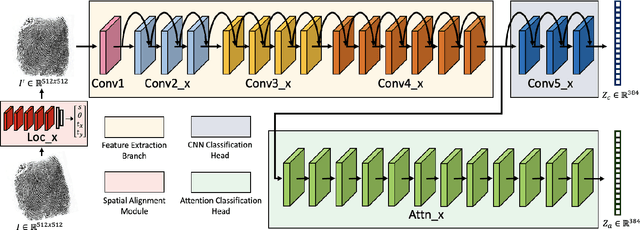
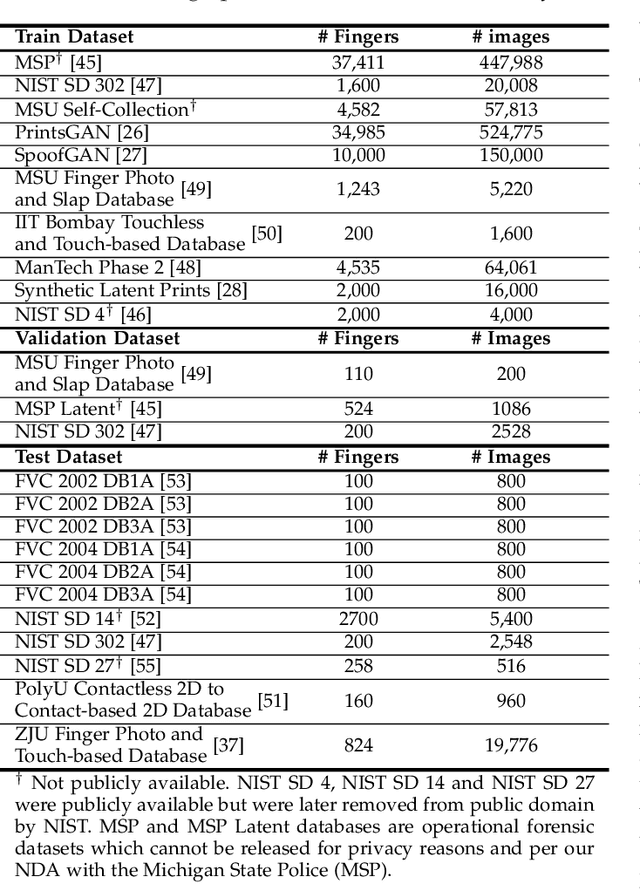
The use of vision transformers (ViT) in computer vision is increasing due to limited inductive biases (e.g., locality, weight sharing, etc.) and increased scalability compared to other deep learning methods. This has led to some initial studies on the use of ViT for biometric recognition, including fingerprint recognition. In this work, we improve on these initial studies for transformers in fingerprint recognition by i.) evaluating additional attention-based architectures, ii.) scaling to larger and more diverse training and evaluation datasets, and iii.) combining the complimentary representations of attention-based and CNN-based embeddings for improved state-of-the-art (SOTA) fingerprint recognition (both authentication and identification). Our combined architecture, AFR-Net (Attention-Driven Fingerprint Recognition Network), outperforms several baseline transformer and CNN-based models, including a SOTA commercial fingerprint system, Verifinger v12.3, across intra-sensor, cross-sensor, and latent to rolled fingerprint matching datasets. Additionally, we propose a realignment strategy using local embeddings extracted from intermediate feature maps within the networks to refine the global embeddings in low certainty situations, which boosts the overall recognition accuracy significantly across each of the models. This realignment strategy requires no additional training and can be applied as a wrapper to any existing deep learning network (including attention-based, CNN-based, or both) to boost its performance.