 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Perturbations Fool Deepfake Detectors
Paper and Code
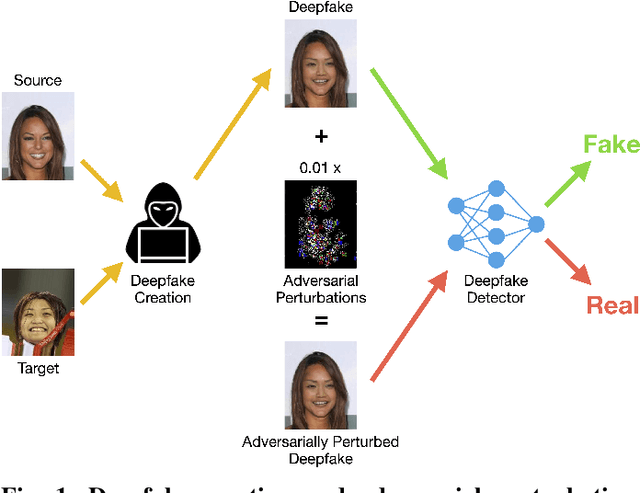

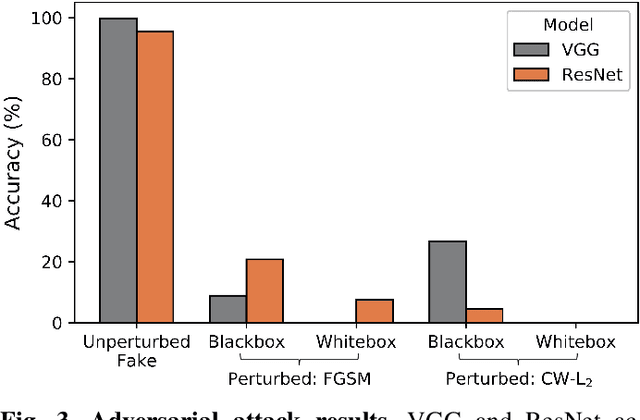
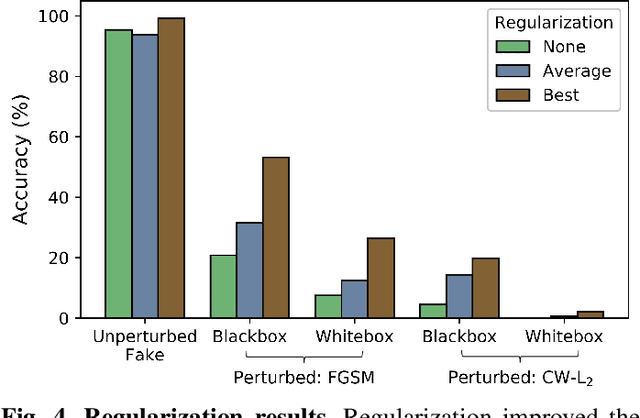
This work uses adversarial perturbations to enhance deepfake images and fool common deepfake detectors. We created adversarial perturbations using the Fast Gradient Sign Method and the Carlini and Wagner L2 norm attack in both blackbox and whitebox settings. Detectors achieved over 95% accuracy on unperturbed deepfakes, but less than 27% accuracy on perturbed deepfakes. We also explore two improvements to deepfake detectors: (i) Lipschitz regularization, and (ii) Deep Image Prior (DIP). Lipschitz regularization constrains the gradient of the detector with respect to the input in order to increase robustness to input perturbations. The DIP defense removes perturbations using generative convolutional neural networks in an unsupervised manner. Regularization improved the detection of perturbed deepfakes on average, including a 10% accuracy boost in the blackbox case. The DIP defense achieved 95% accuracy on perturbed deepfakes that fooled the original detector, while retaining 98% accuracy in other cases on a 100 image subsample.