 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Fine-tuning for Backdoor Defense: Connect Adversarial Examples to Triggered Samples
Paper and Code
Feb 13, 2022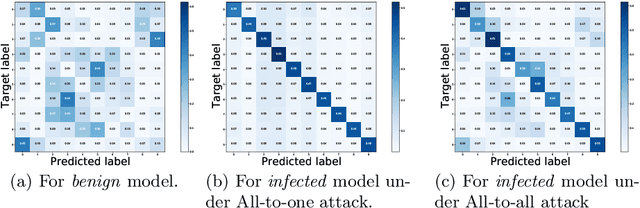

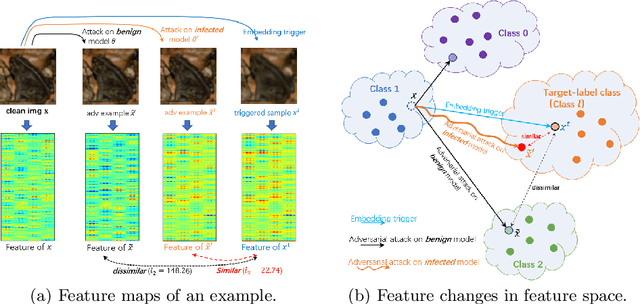

Deep neural networks (DNNs) are known to be vulnerable to backdoor attacks, i.e., a backdoor trigger planted at training time, the infected DNN model would misclassify any testing sample embedded with the trigger as target label. Due to the stealthiness of backdoor attacks, it is hard either to detect or erase the backdoor from infected models. In this paper, we propose a new Adversarial Fine-Tuning (AFT) approach to erase backdoor triggers by leveraging adversarial examples of the infected model. For an infected model, we observe that its adversarial examples have similar behaviors as its triggered samples. Based on such observation, we design the AFT to break the foundation of the backdoor attack (i.e., the strong correlation between a trigger and a target label). We empirically show that, against 5 state-of-the-art backdoor attacks, AFT can effectively erase the backdoor triggers without obvious performance degradation on clean samples, which significantly outperforms existing defense methods.