 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial defenses via a mixture of generators
Paper and Code
Oct 05, 2021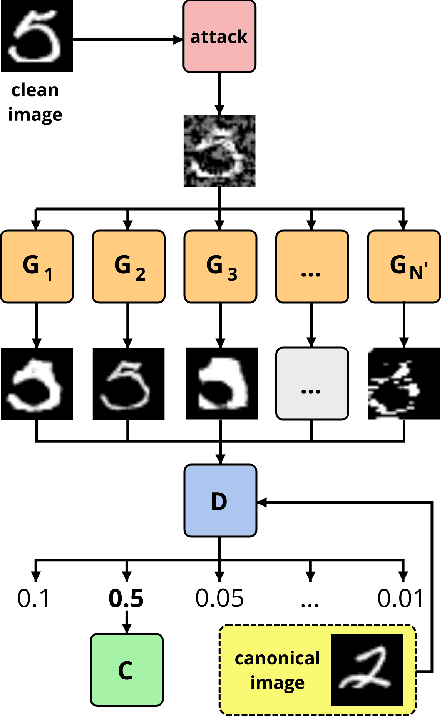


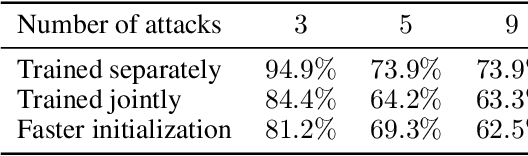
In spite of the enormous success of neural networks, adversarial examples remain a relatively weakly understood feature of deep learning systems. There is a considerable effort in both building more powerful adversarial attacks and designing methods to counter the effects of adversarial examples. We propose a method to transform the adversarial input data through a mixture of generators in order to recover the correct class obfuscated by the adversarial attack. A canonical set of images is used to generate adversarial examples through potentially multiple attacks. Such transformed images are processed by a set of generators, which are trained adversarially as a whole to compete in inverting the initial transformations. To our knowledge, this is the first use of a mixture-based adversarially trained system as a defense mechanism. We show that it is possible to train such a system without supervision, simultaneously on multiple adversarial attacks. Our system is able to recover class information for previously-unseen examples with neither attack nor data labels on the MNIST dataset. The results demonstrate that this multi-attack approach is competitive with adversarial defenses tested in single-attack settings.