 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Approximate Inference for Speech to Electroglottograph Conversion
Paper and Code
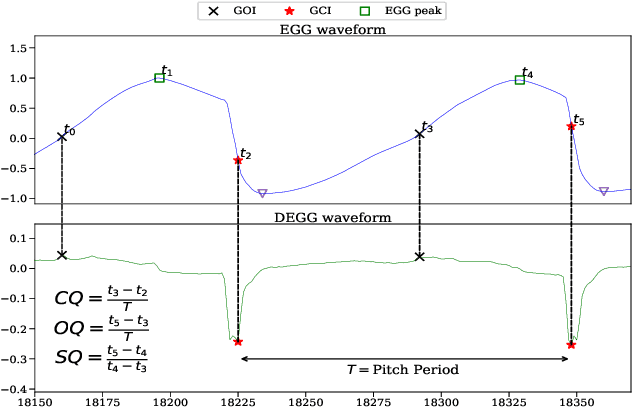
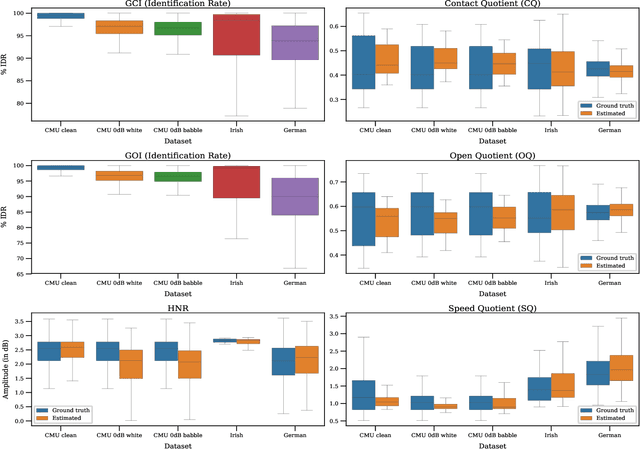

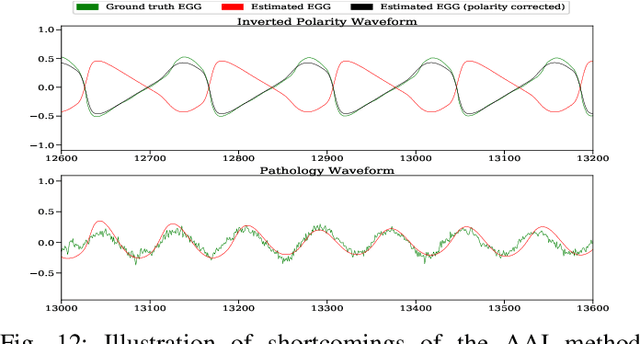
Speech produced by human vocal apparatus conveys substantial non-semantic information including the gender of the speaker, voice quality, affective state, abnormalities in the vocal apparatus etc. Such information is attributed to the properties of the voice source signal, which is usually estimated from the speech signal. However, most of the source estimation techniques depend heavily on the goodness of the model assumptions and are prone to noise. A popular alternative is to indirectly obtain the source information through the Electroglottographic (EGG) signal that measures the electrical admittance around the vocal folds using a dedicated hardware. In this paper, we address the problem of estimating the EGG signal directly from the speech signal, devoid of any hardware. Sampling from the intractable conditional distribution of the EGG signal given the speech signal is accomplished through optimization of an evidence lower bound. This is constructed via minimization of the KL-divergence between the true and the approximated posteriors of a latent variable learned using a deep neural auto-encoder that serves an informative prior which reconstructs the EGG signal. We demonstrate the efficacy of the method to generate EGG signal by conducting several experiments on datasets comprising multiple speakers, voice qualities, noise settings and speech pathologies. The proposed method is evaluated on many benchmark metrics and is found to agree with the gold standards while being better than the state-of-the-art algorithms on a few tasks such as epoch extraction.