 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjusted Asymmetric Accuracy: A Well-Behaving External Cluster Validity Measure
Paper and Code
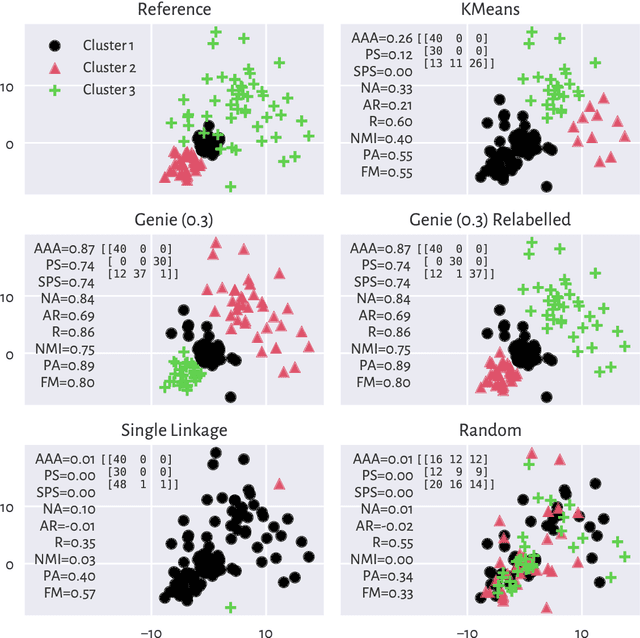
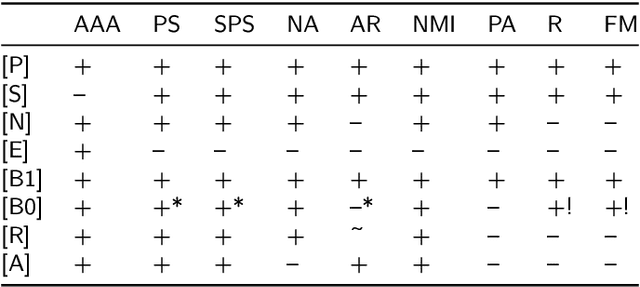
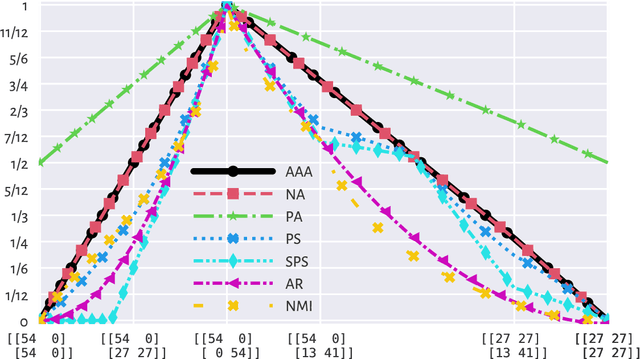
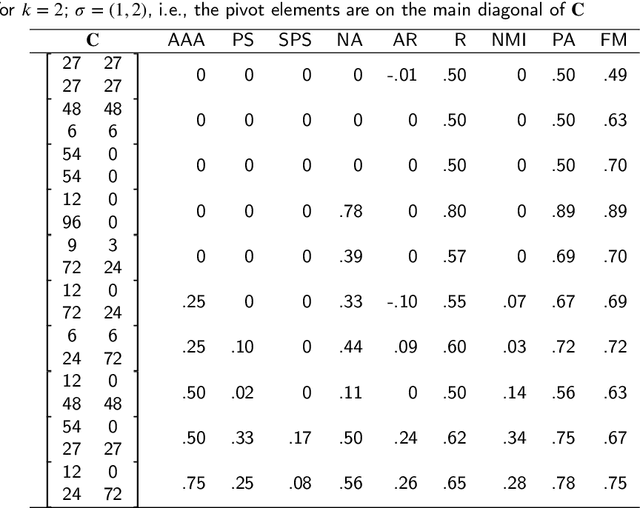
There is no, nor will there ever be, single best clustering algorithm, but we would still like to be able to pinpoint those which are well-performing on certain task types and filter out the systematically disappointing ones. Clustering algorithms are traditionally evaluated using either internal or external validity measures. Internal measures quantify different aspects of the obtained partitions, e.g., the average degree of cluster compactness or point separability. Yet, their validity is questionable because the clusterings they promote can sometimes be meaningless. External measures, on the other hand, compare the algorithms' outputs to the reference, ground truth groupings that are provided by experts. The commonly-used classical partition similarity scores, such as the normalised mutual information, Fowlkes-Mallows, or adjusted Rand index, might not possess all the desirable properties, e.g., they do not identify pathological edge cases correctly. Furthermore, they are not nicely interpretable: it is hard to say what a score of 0.8 really means. Its behaviour might also vary as the number of true clusters changes. This makes comparing clustering algorithms across many benchmark datasets difficult. To remedy this, we propose and analyse a new measure: an asymmetric version of the optimal set-matching accuracy. It is corrected for chance and the imbalancedness of cluster sizes.