 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Randomness in Evaluation Protocols for Out-of-Distribution Detection
Paper and Code
Mar 01, 2022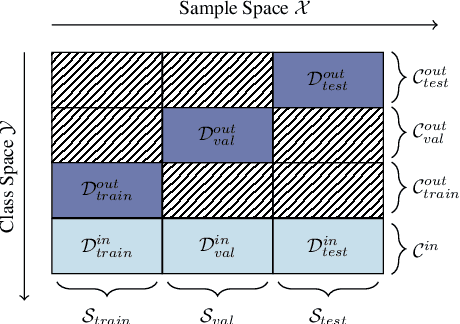
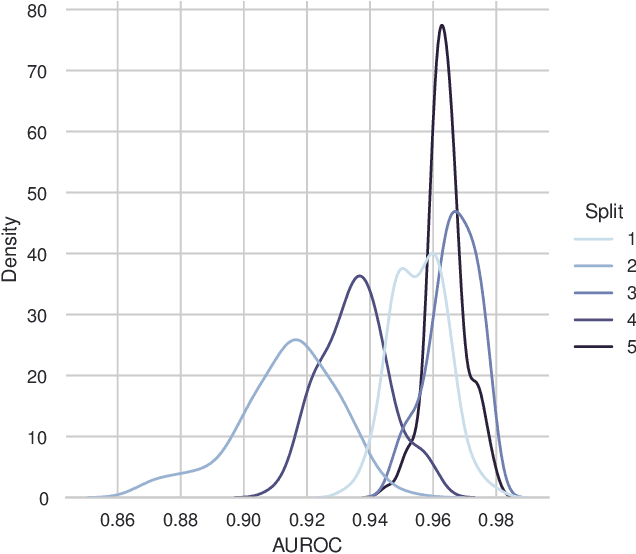
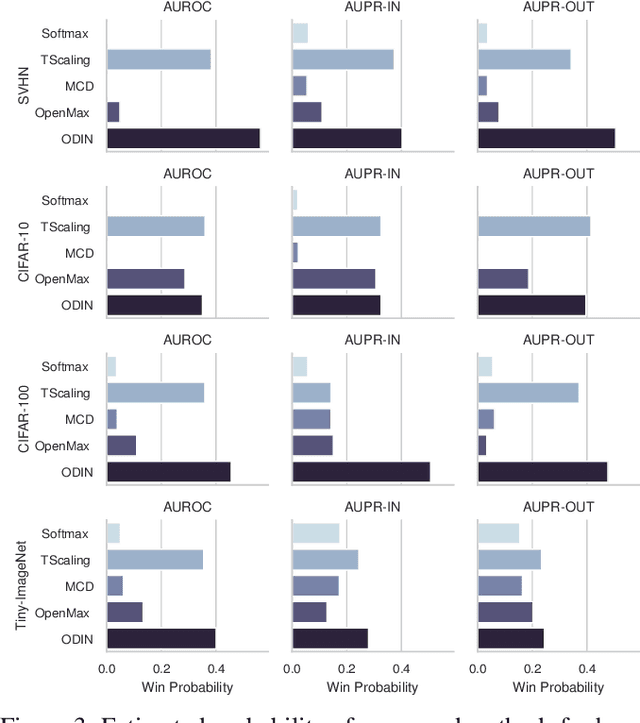
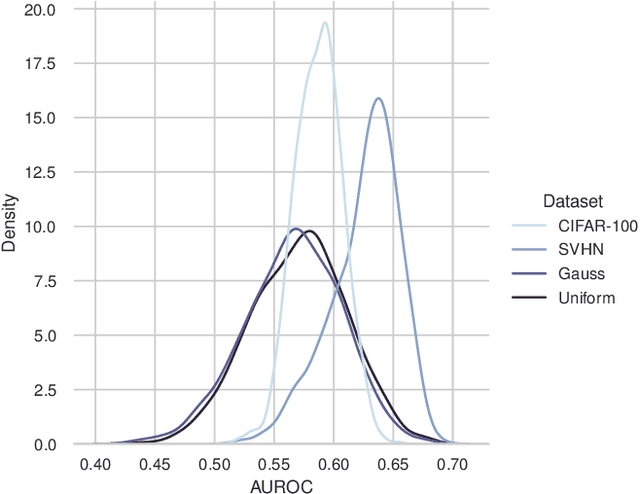
Deep Neural Networks for classification behave unpredictably when confronted with inputs not stemming from the training distribution. This motivates out-of-distribution detection (OOD) mechanisms. The usual lack of prior information on out-of-distribution data renders the performance estimation of detection approaches on unseen data difficult. Several contemporary evaluation protocols are based on open set simulations, which average the performance over up to five synthetic random splits of a dataset into in- and out-of-distribution samples. However, the number of possible splits may be much larger, and the performance of Deep Neural Networks is known to fluctuate significantly depending on different sources of random variation. We empirically demonstrate that current protocols may fail to provide reliable estimates of the expected performance of OOD methods. By casting this evaluation as a random process, we generalize the concept of open set simulations and propose to estimate the performance of OOD methods using a Monte Carlo approach that addresses the randomness.