 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Census data problems in race imputation via fully Bayesian Improved Surname Geocoding and name supplements
Paper and Code
May 12, 2022
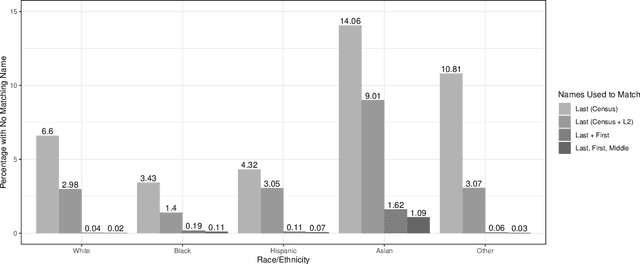

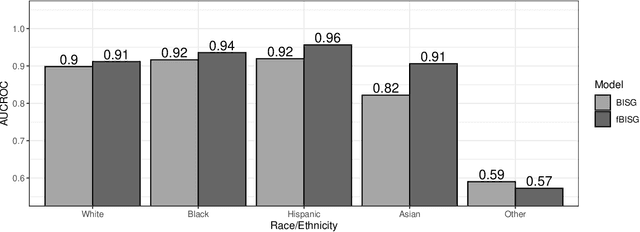
Prediction of an individual's race and ethnicity plays an important role in social science and public health research. Examples include studies of racial disparity in health and voting. Recently, Bayesian Improved Surname Geocoding (BISG), which uses Bayes' rule to combine information from Census surname files with the geocoding of an individual's residence, has emerged as a leading methodology for this prediction task. Unfortunately, BISG suffers from two Census data problems that contribute to unsatisfactory predictive performance for minorities. First, the decennial Census often contains zero counts for minority racial groups in the Census blocks where some members of those groups reside. Second, because the Census surname files only include frequent names, many surnames -- especially those of minorities -- are missing from the list. To address the zero counts problem, we introduce a fully Bayesian Improved Surname Geocoding (fBISG) methodology that accounts for potential measurement error in Census counts by extending the na\"ive Bayesian inference of the BISG methodology to full posterior inference. To address the missing surname problem, we supplement the Census surname data with additional data on last, first, and middle names taken from the voter files of six Southern states where self-reported race is available. Our empirical validation shows that the fBISG methodology and name supplements significantly improve the accuracy of race imputation across all racial groups, and especially for Asians. The proposed methodology, together with additional name data, is available via the open-source software package wru.