 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdditive function approximation in the brain
Paper and Code
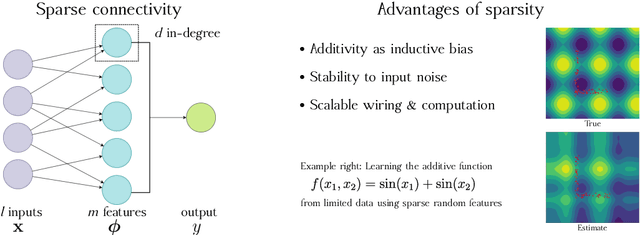



Many biological learning systems such as the mushroom body, hippocampus, and cerebellum are built from sparsely connected networks of neurons. For a new understanding of such networks, we study the function spaces induced by sparse random features and characterize what functions may and may not be learned. A network with $d$ inputs per neuron is found to be equivalent to an additive model of order $d$, whereas with a degree distribution the network combines additive terms of different orders. We identify three specific advantages of sparsity: additive function approximation is a powerful inductive bias that limits the curse of dimensionality, sparse networks are stable to outlier noise in the inputs, and sparse random features are scalable. Thus, even simple brain architectures can be powerful function approximators. Finally, we hope that this work helps popularize kernel theories of networks among computational neuroscientists.