 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Stress Testing without Domain Heuristics using Go-Explore
Paper and Code
Apr 08, 2020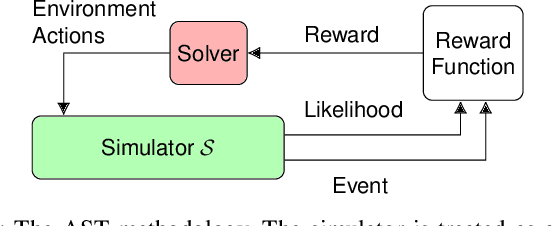

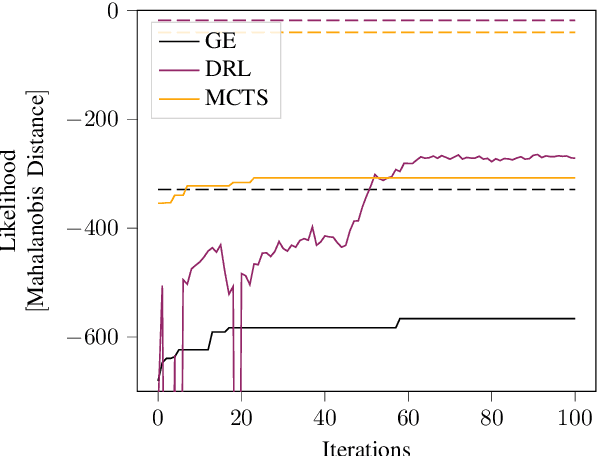
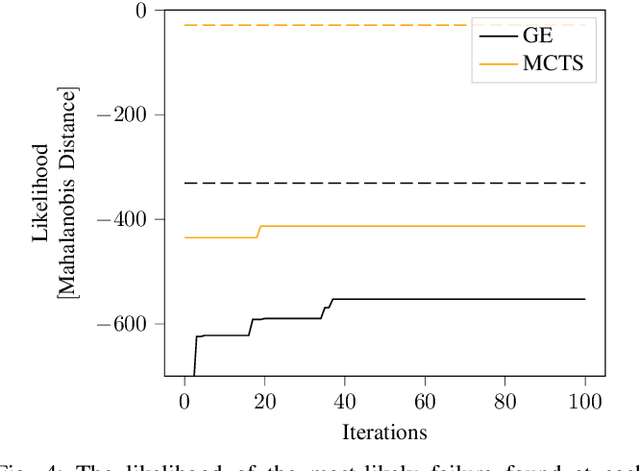
Recently, reinforcement learning (RL) has been used as a tool for finding failures in autonomous systems. During execution, the RL agents often rely on some domain-specific heuristic reward to guide them towards finding failures, but constructing such a heuristic may be difficult or infeasible. Without a heuristic, the agent may only receive rewards at the time of failure, or even rewards that guide it away from failures. For example, some approaches give rewards for taking more-likely actions, because we want to find more-likely failures. However, the agent may then learn to only take likely actions, and may not be able to find a failure at all. Consequently, the problem becomes a hard-exploration problem, where rewards do not aid exploration. A new algorithm, go-explore (GE), has recently set new records on benchmarks from the hard-exploration field. We apply GE to adaptive stress testing (AST), one example of an RL-based falsification approach that provides a way to search for the most-likely failure scenario. We simulate a scenario where an autonomous vehicle drives while a pedestrian is crossing the road. We demonstrate that GE is able to find failures without domain-specific heuristics, such as the distance between the car and the pedestrian, on scenarios that other RL techniques are unable to solve. Furthermore, inspired by the robustification phase of GE, we demonstrate that the backwards algorithm (BA) improves the failures found by other RL techniques.