Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Stochastic Optimization
Paper and Code
Jan 18, 2020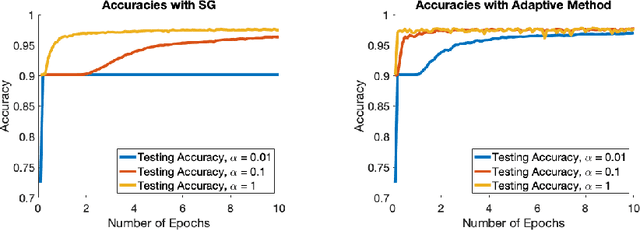
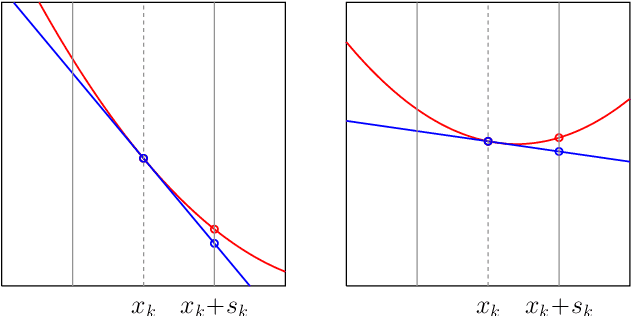
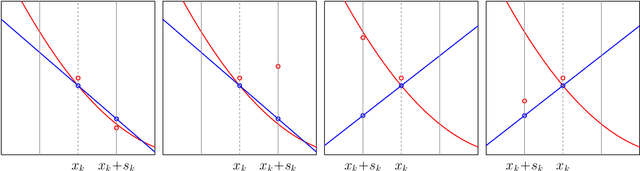
Optimization lies at the heart of machine learning and signal processing. Contemporary approaches based on the stochastic gradient method are non-adaptive in the sense that their implementation employs prescribed parameter values that need to be tuned for each application. This article summarizes recent research and motivates future work on adaptive stochastic optimization methods, which have the potential to offer significant computational savings when training large-scale systems.
View paper on