 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Optimization Algorithms for Machine Learning
Paper and Code


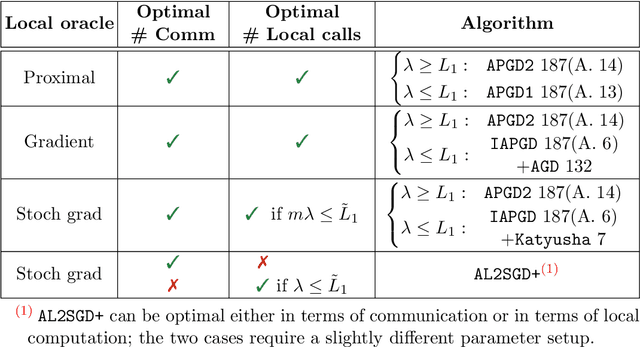

Machine learning assumes a pivotal role in our data-driven world. The increasing scale of models and datasets necessitates quick and reliable algorithms for model training. This dissertation investigates adaptivity in machine learning optimizers. The ensuing chapters are dedicated to various facets of adaptivity, including: 1. personalization and user-specific models via personalized loss, 2. provable post-training model adaptations via meta-learning, 3. learning unknown hyperparameters in real time via hyperparameter variance reduction, 4. fast O(1/k^2) global convergence of second-order methods via stepsized Newton method regardless of the initialization and choice basis, 5. fast and scalable second-order methods via low-dimensional updates. This thesis contributes novel insights, introduces new algorithms with improved convergence guarantees, and improves analyses of popular practical algorithms.