 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Bayesian Shrinkage Estimation Using Log-Scale Shrinkage Priors
Paper and Code
Jan 08, 2018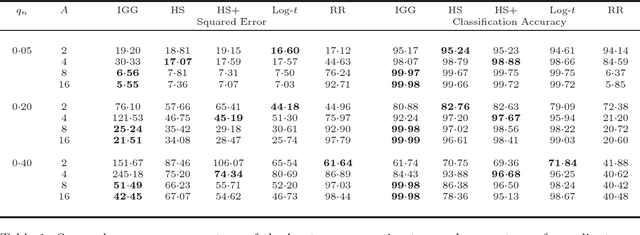
Global-local shrinkage hierarchies are an important, recent innovation in Bayesian estimation of regression models. In this paper we propose to use log-scale distributions as a basis for generating familes of flexible prior distributions for the local shrinkage hyperparameters within such hierarchies. An important property of the log-scale priors is that by varying the scale parameter one may vary the degree to which the prior distribution promotes sparsity in the coefficient estimates, all the way from the simple proportional shrinkage ridge regression model up to extremely heavy tailed, sparsity inducing prior distributions. By examining the class of distributions over the logarithm of the local shrinkage parameter that have log-linear, or sub-log-linear tails, we show that many of standard prior distributions for local shrinkage parameters can be unified in terms of the tail behaviour and concentration properties of their corresponding marginal distributions over the coefficients $\beta_j$. We use these results to derive upper bounds on the rate of concentration around $|\beta_j|=0$, and the tail decay as $|\beta_j| \to \infty$, achievable by this class of prior distributions. We then propose a new type of ultra-heavy tailed prior, called the log-$t$ prior, which exhibits the property that, irrespective of the choice of associated scale parameter, the induced marginal distribution over $\beta_j$ always diverge at $\beta_j = 0$, and always possesses super-Cauchy tails. Finally, we propose to incorporate the scale parameter in the log-scale prior distributions into the Bayesian hierarchy and derive an adaptive shrinkage procedure. Simulations show that in contrast to a number of standard prior distributions, our adaptive log-$t$ procedure appears to always perform well, irrespective of the level of sparsity or signal-to-noise ratio of the underlying model.