 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting End-to-End Neural Speaker Verification to New Languages and Recording Conditions with Adversarial Training
Paper and Code
Nov 07, 2018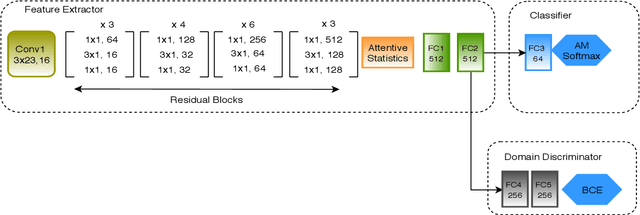
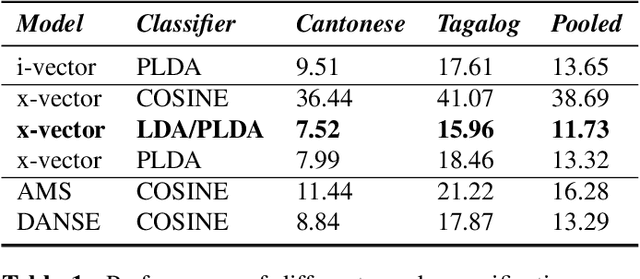

In this article we propose a novel approach for adapting speaker embeddings to new domains based on adversarial training of neural networks. We apply our embeddings to the task of text-independent speaker verification, a challenging, real-world problem in biometric security. We further the development of end-to-end speaker embedding models by combing a novel 1-dimensional, self-attentive residual network, an angular margin loss function and adversarial training strategy. Our model is able to learn extremely compact, 64-dimensional speaker embeddings that deliver competitive performance on a number of popular datasets using simple cosine distance scoring. One the NIST-SRE 2016 task we are able to beat a strong i-vector baseline, while on the Speakers in the Wild task our model was able to outperform both i-vector and x-vector baselines, showing an absolute improvement of 2.19% over the latter. Additionally, we show that the integration of adversarial training consistently leads to a significant improvement over an unadapted model.