 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-SISE: Adaptive Semantic Input Sampling for Efficient Explanation of Convolutional Neural Networks
Paper and Code
Feb 15, 2021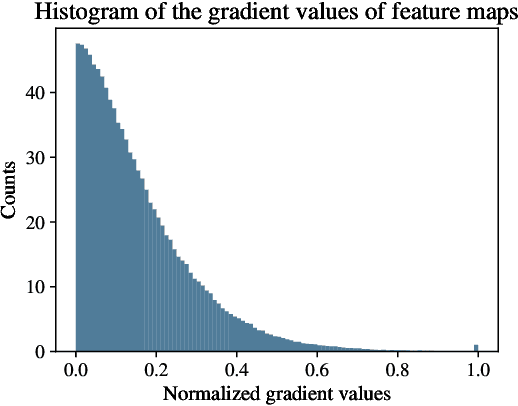
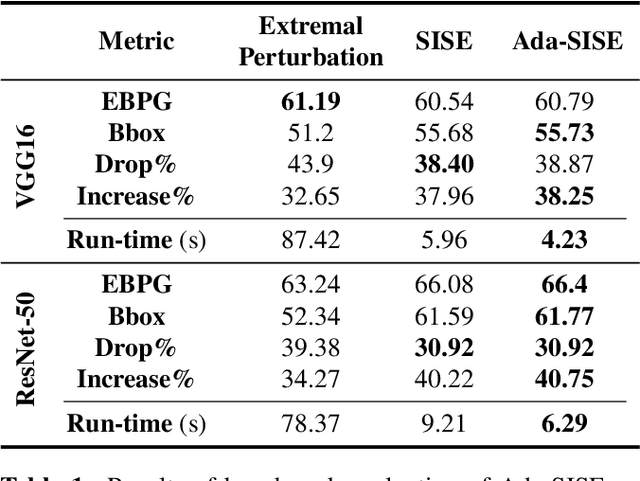
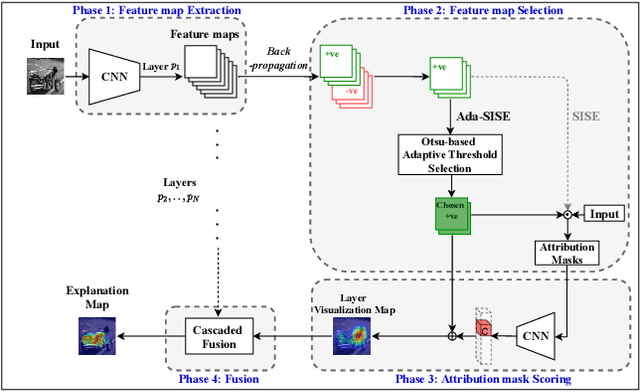

Explainable AI (XAI) is an active research area to interpret a neural network's decision by ensuring transparency and trust in the task-specified learned models. Recently, perturbation-based model analysis has shown better interpretation, but backpropagation techniques are still prevailing because of their computational efficiency. In this work, we combine both approaches as a hybrid visual explanation algorithm and propose an efficient interpretation method for convolutional neural networks. Our method adaptively selects the most critical features that mainly contribute towards a prediction to probe the model by finding the activated features. Experimental results show that the proposed method can reduce the execution time up to 30% while enhancing competitive interpretability without compromising the quality of explanation generated.