 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive PETs: Active Data Annotation Prioritisation for Few-Shot Claim Verification with Pattern Exploiting Training
Paper and Code
Aug 18, 2022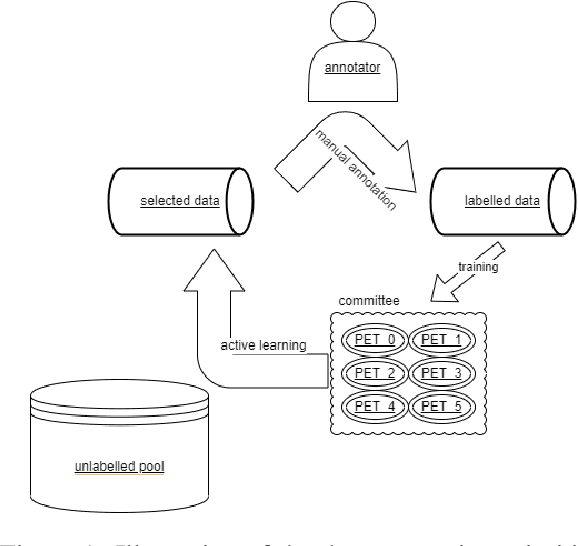
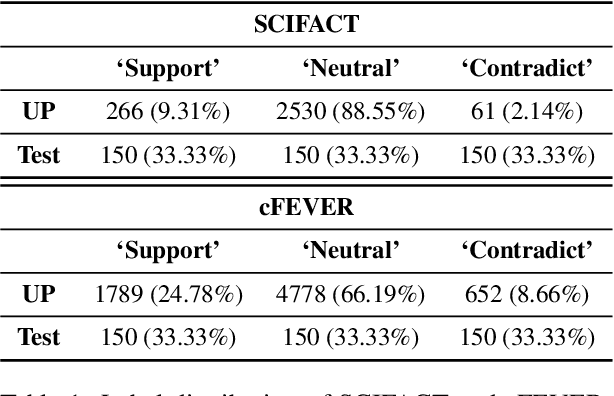
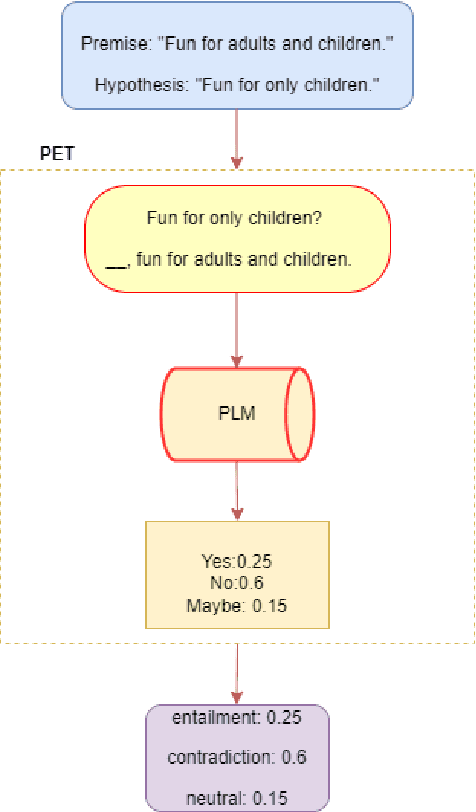
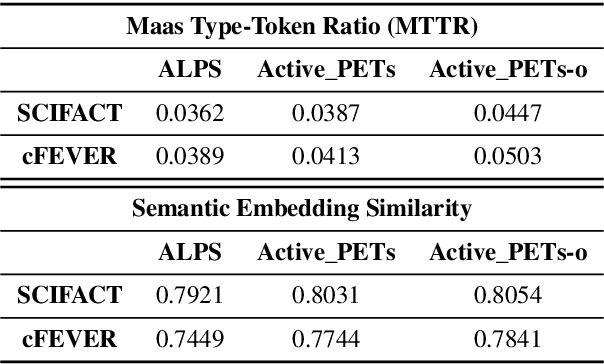
To mitigate the impact of data scarcity on fact-checking systems, we focus on few-shot claim verification. Despite recent work on few-shot classification by proposing advanced language models, there is a dearth of research in data annotation prioritisation that improves the selection of the few shots to be labelled for optimal model performance. We propose Active PETs, a novel weighted approach that utilises an ensemble of Pattern Exploiting Training (PET) models based on various language models, to actively select unlabelled data as candidates for annotation. Using Active PETs for data selection shows consistent improvement over the state-of-the-art active learning method, on two technical fact-checking datasets and using six different pretrained language models. We show further improvement with Active PETs-o, which further integrates an oversampling strategy. Our approach enables effective selection of instances to be labelled where unlabelled data is abundant but resources for labelling are limited, leading to consistently improved few-shot claim verification performance. Our code will be available upon publication.