 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Stochastic Gradient Descent Using Antithetic Sampling
Paper and Code
Oct 07, 2018

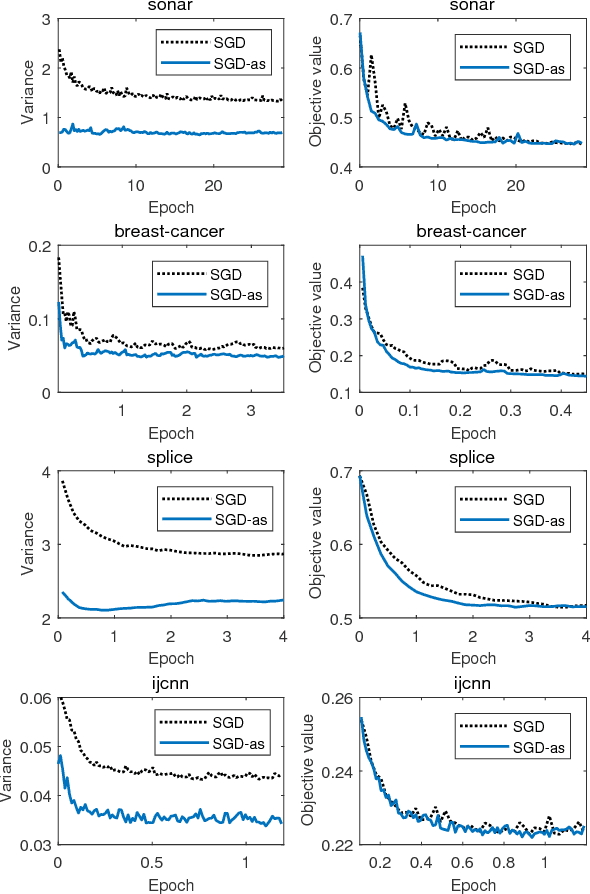

(Mini-batch) Stochastic Gradient Descent is a popular optimization method which has been applied to many machine learning applications. But a rather high variance introduced by the stochastic gradient in each step may slow down the convergence. In this paper, we propose the antithetic sampling strategy to reduce the variance by taking advantage of the internal structure in dataset. Under this new strategy, stochastic gradients in a mini-batch are no longer independent but negatively correlated as much as possible, while the mini-batch stochastic gradient is still an unbiased estimator of full gradient. For the binary classification problems, we just need to calculate the antithetic samples in advance, and reuse the result in each iteration, which is practical. Experiments are provided to confirm the effectiveness of the proposed method.