Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerate Distributed Stochastic Descent for Nonconvex Optimization with Momentum
Paper and Code
Oct 01, 2021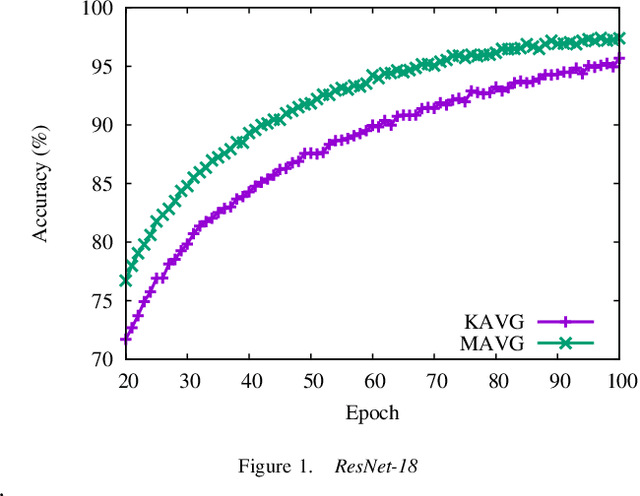
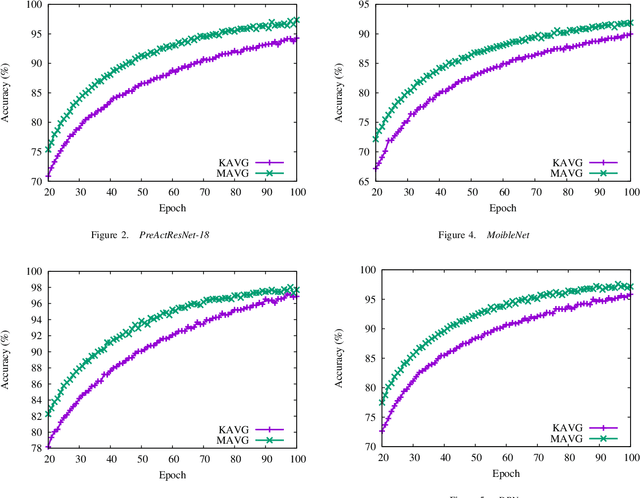
Momentum method has been used extensively in optimizers for deep learning. Recent studies show that distributed training through K-step averaging has many nice properties. We propose a momentum method for such model averaging approaches. At each individual learner level traditional stochastic gradient is applied. At the meta-level (global learner level), one momentum term is applied and we call it block momentum. We analyze the convergence and scaling properties of such momentum methods. Our experimental results show that block momentum not only accelerates training, but also achieves better results.
View paper on