 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Parent Model for Low-Resource Neural Machine Translation Transfer
Paper and Code
Sep 20, 2019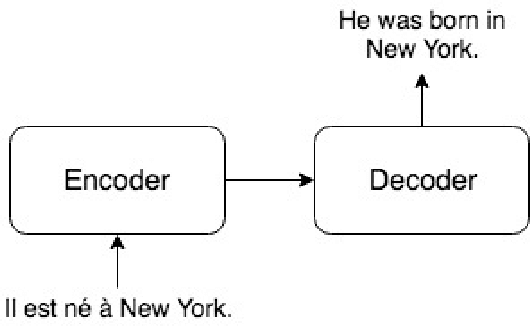
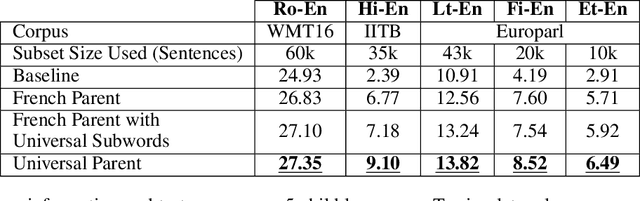
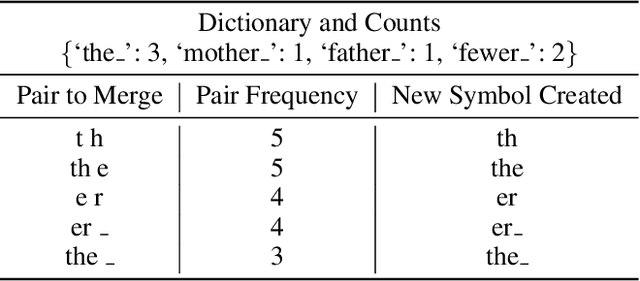
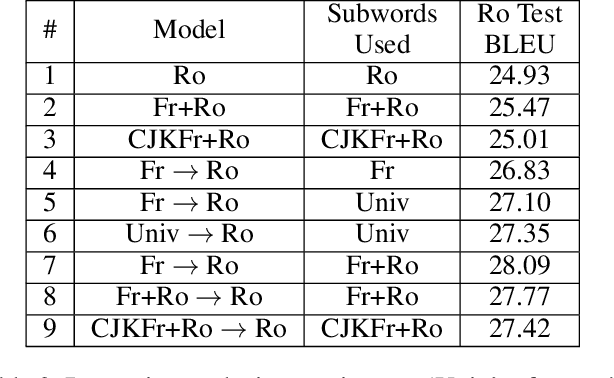
Transfer learning from a high-resource language pair `parent' has been proven to be an effective way to improve neural machine translation quality for low-resource language pairs `children.' However, previous approaches build a custom parent model or at least update an existing parent model's vocabulary for each child language pair they wish to train, in an effort to align parent and child vocabularies. This is not a practical solution. It is wasteful to devote the majority of training time for new language pairs to optimizing parameters on an unrelated data set. Further, this overhead reduces the utility of neural machine translation for deployment in humanitarian assistance scenarios, where extra time to deploy a new language pair can mean the difference between life and death. In this work, we present a `universal' pre-trained neural parent model with constant vocabulary that can be used as a starting point for training practically any new low-resource language to a fixed target language. We demonstrate that our approach, which leverages orthography unification and a broad-coverage approach to subword identification, generalizes well to several languages from a variety of families, and that translation systems built with our approach can be built more quickly than competing methods and with better quality as well.