 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Framework of Bilinear LSTMs
Paper and Code
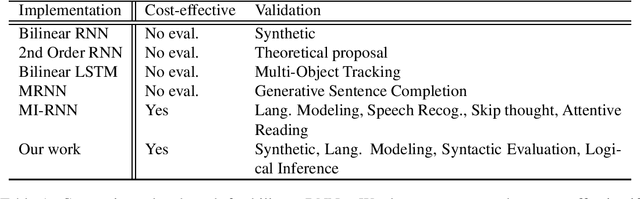
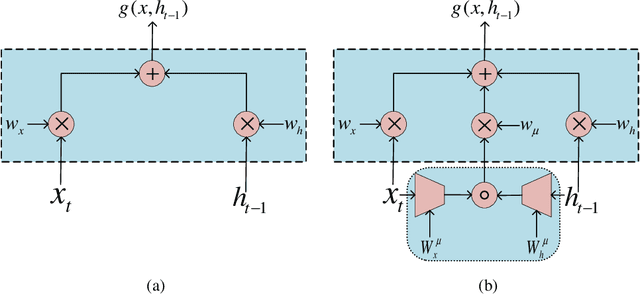
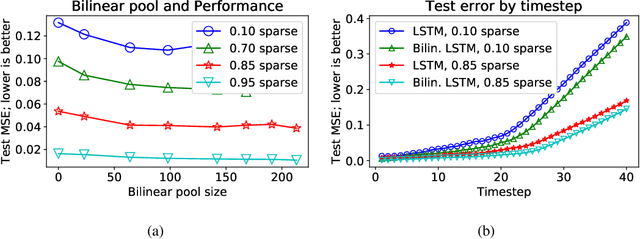

This paper presents a novel unifying framework of bilinear LSTMs that can represent and utilize the nonlinear interaction of the input features present in sequence datasets for achieving superior performance over a linear LSTM and yet not incur more parameters to be learned. To realize this, our unifying framework allows the expressivity of the linear vs. bilinear terms to be balanced by correspondingly trading off between the hidden state vector size vs. approximation quality of the weight matrix in the bilinear term so as to optimize the performance of our bilinear LSTM, while not incurring more parameters to be learned. We empirically evaluate the performance of our bilinear LSTM in several language-based sequence learning tasks to demonstrate its general applicability.