 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified DRO View of Multi-class Loss Functions with top-N Consistency
Paper and Code

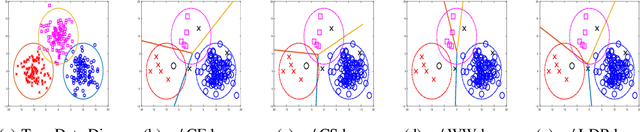
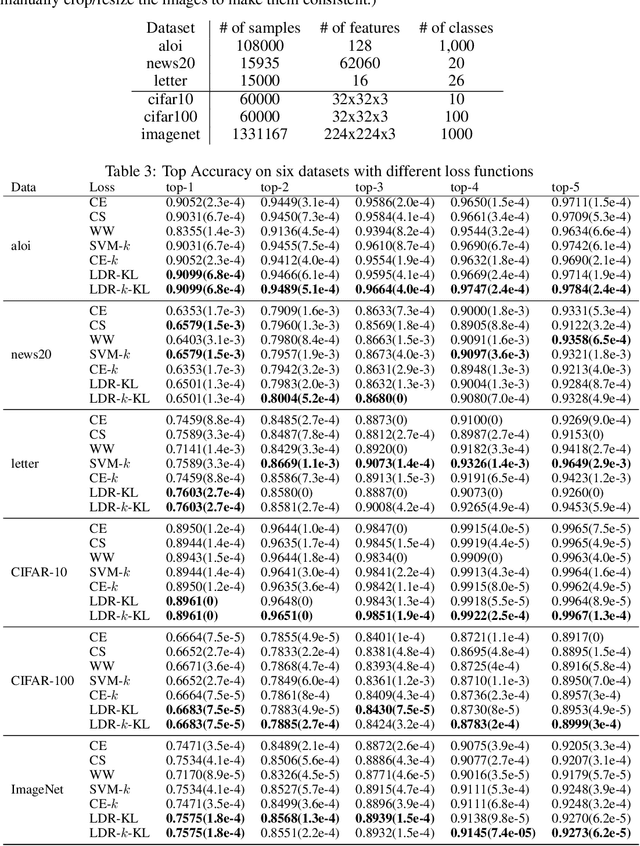
Multi-class classification is one of the most common tasks in machine learning applications, where data is labeled by one of many class labels. Many loss functions have been proposed for multi-class classification including two well-known ones, namely the cross-entropy (CE) loss and the crammer-singer (CS) loss (aka. the SVM loss). While CS loss has been used widely for traditional machine learning tasks, CE loss is usually a default choice for multi-class deep learning tasks. There are also top-$k$ variants of CS loss and CE loss that are proposed to promote the learning of a classifier for achieving better top-$k$ accuracy. Nevertheless, it still remains unclear the relationship between these different losses, which hinders our understanding of their expectations in different scenarios. In this paper, we present a unified view of the CS/CE losses and their smoothed top-$k$ variants by proposing a new family of loss functions, which are arguably better than the CS/CE losses when the given label information is incomplete and noisy. The new family of smooth loss functions named {label-distributionally robust (LDR) loss} is defined by leveraging the distributionally robust optimization (DRO) framework to model the uncertainty in the given label information, where the uncertainty over true class labels is captured by using distributional weights for each label regularized by a function.