 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition
Paper and Code
Aug 15, 2020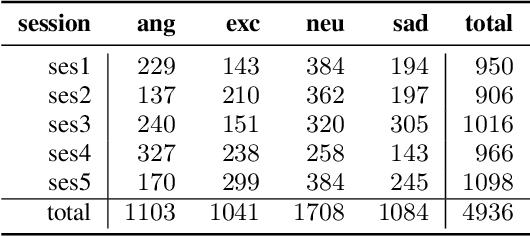


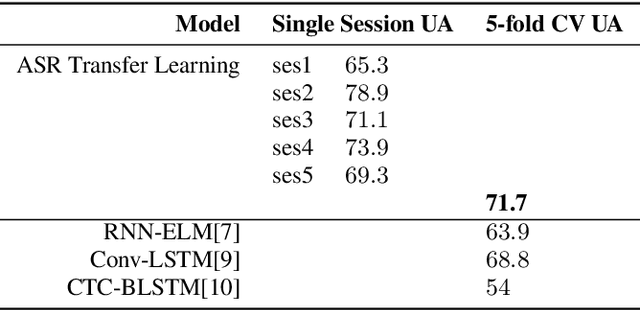
This paper presents a transfer learning method in speech emotion recognition based on a Time-Delay Neural Network (TDNN) architecture. A major challenge in the current speech-based emotion detection research is data scarcity. The proposed method resolves this problem by applying transfer learning techniques in order to leverage data from the automatic speech recognition (ASR) task for which ample data is available. Our experiments also show the advantage of speaker-class adaptation modeling techniques by adopting identity-vector (i-vector) based features in addition to standard Mel-Frequency Cepstral Coefficient (MFCC) features.[1] We show the transfer learning models significantly outperform the other methods without pretraining on ASR. The experiments performed on the publicly available IEMOCAP dataset which provides 12 hours of motional speech data. The transfer learning was initialized by using the Ted-Lium v.2 speech dataset providing 207 hours of audio with the corresponding transcripts. We achieve the highest significantly higher accuracy when compared to state-of-the-art, using five-fold cross validation. Using only speech, we obtain an accuracy 71.7% for anger, excitement, sadness, and neutrality emotion content.