 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Principles, Models and Methods for Learning from Irregularly Sampled Time Series
Paper and Code
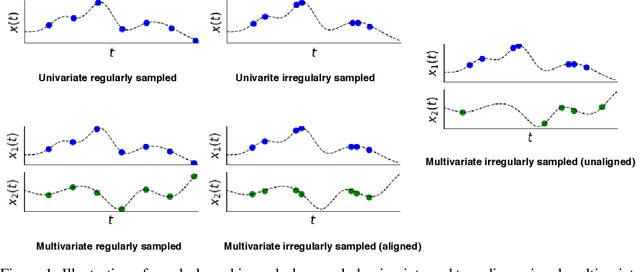
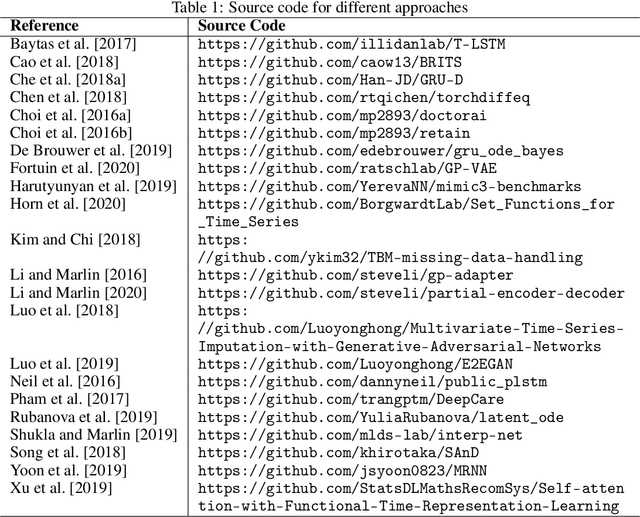
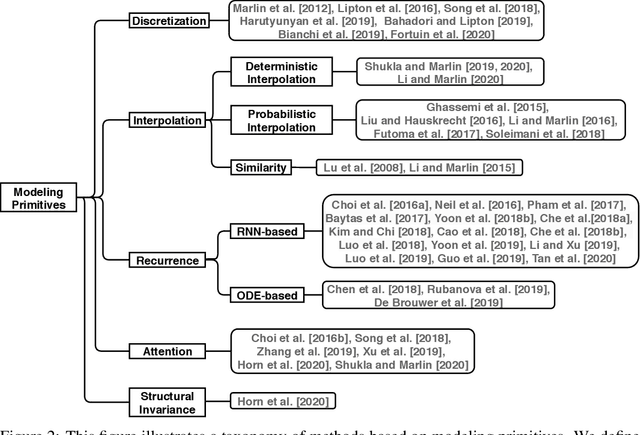
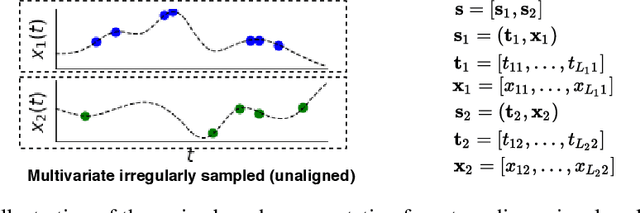
Irregularly sampled time series data arise naturally in many application domains including biology, ecology, climate science, astronomy, and health. Such data represent fundamental challenges to many classical models from machine learning and statistics due to the presence of non-uniform intervals between observations. However, there has been significant progress within the machine learning community over the last decade on developing specialized models and architectures for learning from irregularly sampled univariate and multivariate time series data. In this survey, we first describe several axes along which approaches to learning from irregularly sampled time series differ including what data representations they are based on, what modeling primitives they leverage to deal with the fundamental problem of irregular sampling, and what inference tasks they are designed to perform. We then survey the recent literature organized primarily along the axis of modeling primitives. We describe approaches based on temporal discretization, interpolation, recurrence, attention and structural invariance. We discuss similarities and differences between approaches and highlight primary strengths and weaknesses.