 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on feature weighting based K-Means algorithms
Paper and Code
Sep 22, 2015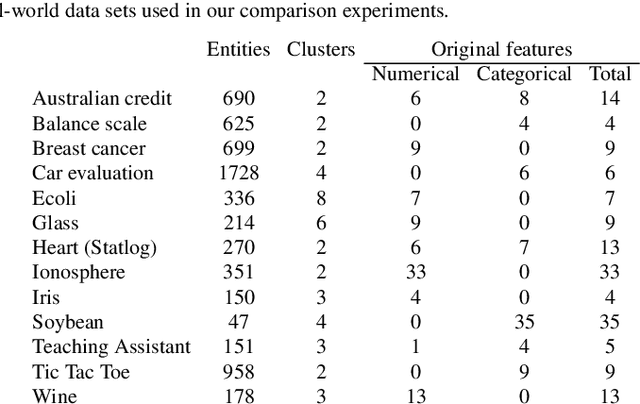
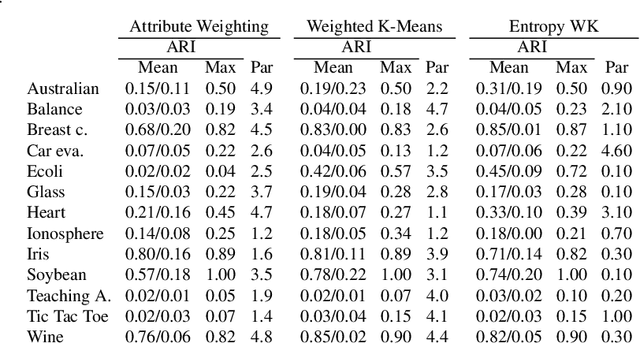
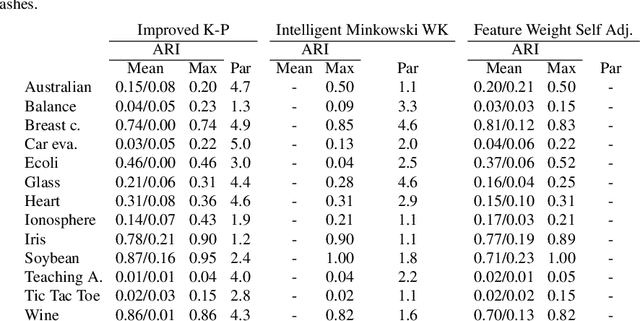
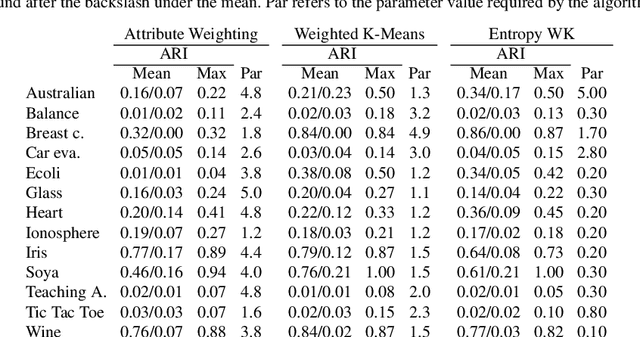
In a real-world data set there is always the possibility, rather high in our opinion, that different features may have different degrees of relevance. Most machine learning algorithms deal with this fact by either selecting or deselecting features in the data preprocessing phase. However, we maintain that even among relevant features there may be different degrees of relevance, and this should be taken into account during the clustering process. With over 50 years of history, K-Means is arguably the most popular partitional clustering algorithm there is. The first K-Means based clustering algorithm to compute feature weights was designed just over 30 years ago. Various such algorithms have been designed since but there has not been, to our knowledge, a survey integrating empirical evidence of cluster recovery ability, common flaws, and possible directions for future research. This paper elaborates on the concept of feature weighting and addresses these issues by critically analysing some of the most popular, or innovative, feature weighting mechanisms based in K-Means.