 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Vision-Language Pre-training from the Lens of Multimodal Machine Translation
Paper and Code
Jun 12, 2023
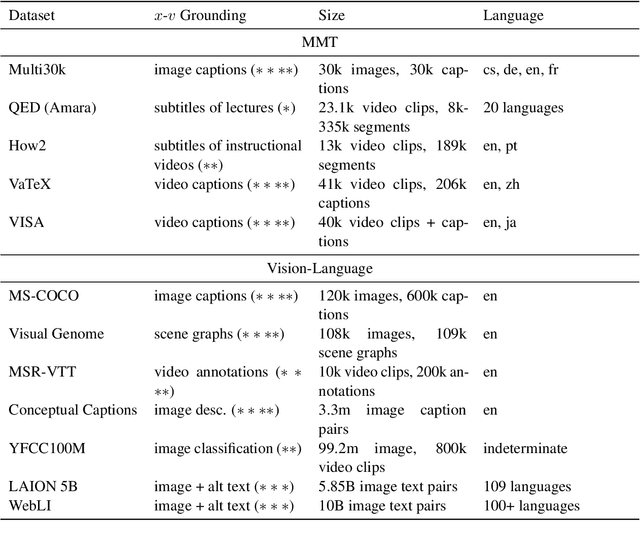
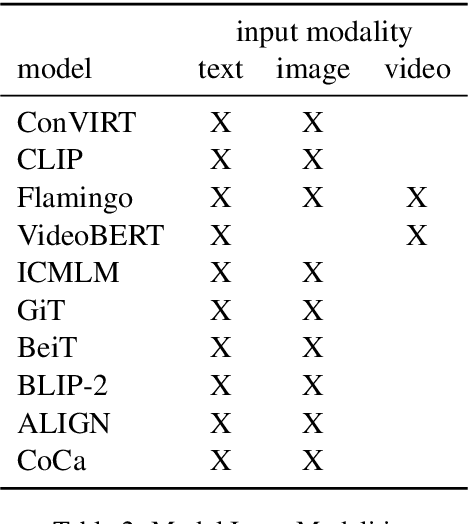
Large language models such as BERT and the GPT series started a paradigm shift that calls for building general-purpose models via pre-training on large datasets, followed by fine-tuning on task-specific datasets. There is now a plethora of large pre-trained models for Natural Language Processing and Computer Vision. Recently, we have seen rapid developments in the joint Vision-Language space as well, where pre-trained models such as CLIP (Radford et al., 2021) have demonstrated improvements in downstream tasks like image captioning and visual question answering. However, surprisingly there is comparatively little work on exploring these models for the task of multimodal machine translation, where the goal is to leverage image/video modality in text-to-text translation. To fill this gap, this paper surveys the landscape of language-and-vision pre-training from the lens of multimodal machine translation. We summarize the common architectures, pre-training objectives, and datasets from literature and conjecture what further is needed to make progress on multimodal machine translation.